Die routinemäßige Verwendung von Patienten‐berichteten Endpunkt‐Maßen zur Verbesserung der Behandlung häufiger, psychischer Störungen bei Erwachsenen
Abstract
Background
Routine outcome monitoring of common mental health disorders (CMHDs), using patient reported outcome measures (PROMs), has been promoted across primary care, psychological therapy and multidisciplinary mental health care settings, but is likely to be costly, given the high prevalence of CMHDs. There has been no systematic review of the use of PROMs in routine outcome monitoring of CMHDs across these three settings.
Objectives
To assess the effects of routine measurement and feedback of the results of PROMs during the management of CMHDs in 1) improving the outcome of CMHDs; and 2) in changing the management of CMHDs.
Search methods
We searched the Cochrane Depression Anxiety and Neurosis group specialised controlled trials register (CCDANCTR‐Studies and CCDANCTR‐References), the Oxford University PROMS Bibliography (2002‐5), Ovid PsycINFO, Web of Science, The Cochrane Library, and International trial registries, initially to 30 May 2014, and updated to 18 May 2015.
Selection criteria
We selected cluster and individually randomised controlled trials (RCTs) including participants with CMHDs aged 18 years and over, in which the results of PROMs were fed back to treating clinicians, or both clinicians and patients. We excluded RCTs in child and adolescent treatment settings, and those in which more than 10% of participants had diagnoses of eating disorders, psychoses, substance use disorders, learning disorders or dementia.
Data collection and analysis
At least two authors independently identified eligible trials, assessed trial quality, and extracted data. We conducted meta‐analysis across studies, pooling outcome measures which were sufficiently similar to each other to justify pooling.
Main results
We included 17 studies involving 8787 participants: nine in multidisciplinary mental health care, six in psychological therapy settings, and two in primary care. Pooling of outcome data to provide a summary estimate of effect across studies was possible only for those studies using the compound Outcome Questionnaire (OQ‐45) or Outcome Rating System (ORS) PROMs, which were all conducted in multidisciplinary mental health care or psychological therapy settings, because both primary care studies identified used single symptom outcome measures, which were not directly comparable to the OQ‐45 or ORS.
Meta‐analysis of 12 studies including 3696 participants using these PROMs found no evidence of a difference in outcome in terms of symptoms, between feedback and no‐feedback groups (standardised mean difference (SMD) ‐0.07, 95% confidence interval (CI) ‐0.16 to 0.01; P value = 0.10). The evidence for this comparison was graded as low quality however, as all included studies were considered at high risk of bias, in most cases due to inadequate blinding of assessors and significant attrition at follow‐up.
Quality of life was reported in only two studies, social functioning in one, and costs in none. Information on adverse events (thoughts of self‐harm or suicide) was collected in one study, but differences between arms were not reported.
It was not possible to pool data on changes in drug treatment or referrals as only two studies reported these. Meta‐analysis of seven studies including 2608 participants found no evidence of a difference in management of CMHDs between feedback and no‐feedback groups, in terms of the number of treatment sessions received (mean difference (MD) ‐0.02 sessions, 95% CI ‐0.42 to 0.39; P value = 0.93). However, the evidence for this comparison was also graded as low quality.
Authors' conclusions
We found insufficient evidence to support the use of routine outcome monitoring using PROMs in the treatment of CMHDs, in terms of improving patient outcomes or in improving management. The findings are subject to considerable uncertainty however, due to the high risk of bias in the large majority of trials meeting the inclusion criteria, which means further research is very likely to have an important impact on the estimate of effect and is likely to change the estimate. More research of better quality is therefore required, particularly in primary care where most CMHDs are treated.
Future research should address issues of blinding of assessors and attrition, and measure a range of relevant symptom outcomes, as well as possible harmful effects of monitoring, health‐related quality of life, social functioning, and costs. Studies should include people treated with drugs as well as psychological therapies, and should follow them up for longer than six months.
PICOs
Laienverständliche Zusammenfassung
Verwendung von Patienten‐berichteten Endpunkt‐Maßen, zur Beobachtung des Fortschritts bei Erwachsenen mit häufigen psychischen Störungen
Warum ist dieser Review wichtig?
Eine von sechs Personen leidet an einer häufigen psychischen Störungen (common mental health disorders (CMHD)), wozu auch Depressionen und Angststörungen gehören. Patienten‐berichtete Endpunkt‐Maße (PROMs) sind Fragebögen zu Symptomen, Funktionsfähigkeit und Beziehungen der Patienten. Die Verwendung von PROMs, um damit Fortschritte bei Menschen mit CMHDs zu beobachten, könnte sowohl Behandlungsendpunkte als auch die Handhabung von CMHDs verbessern.
Zielgruppe des Reviews
Menschen mit CMHDs; Gesundheitsexperten aus der medizinischen Grundversorgung, der Psychotherapie und psychologischen Gesundheitsdiensten; Gesundheitsbeauftragte.
Welche Fragen soll dieser Review beantworten?
Verbessert die Verwendung von PROMs zur Beobachtung von Fortschritten bei Menschen mit CMHDs gesundheitsrelevante Endpunkte einschließlich Symptomen, Lebensqualität und sozialer Fähigkeiten?
Ändert die Verwendung von PROMs bei Menschen mit CMHD die Art und Weise mit der ihren Problemen begegnet wird, einschließlich medikamentöser Therapie und Überweisungen an Spezialisten?
Welche Studien wurden in diesen Review eingeschlossen?
Studien‐Datenbanken wurden durchsucht, um alle Studien mit hoher Qualität zu finden, in denen PROMs verwendet wurden, um die Behandlung von CMHDs zu beobachten und die bis Mai 2015 publiziert wurden. Es wurden nur randomisierte, kontrollierte Studien an Erwachsenen eingeschlossen, bei denen mehrheitlich eine CMHD diagnostiziert wurde.
17 Studien mit insgesamt 8.787 Teilnehmern wurden in den Review eingeschlossen, 9 aus dem Bereich psychische Gesundheit, 6 aus der Psychotherapie und 2 aus der medizinischen Grundversorgung.
Die Qualität der Studien wurde von ‘niedrig’ bis ‘moderat’ bewertet.
Was besagt die Evidenz aus diesem Review?
Ob die routinemäßige Beobachtung von CMHDs mit PROMs hilfreich ist, konnte in der Analyse, welche die Studienergebnisse entweder bezüglich der Verbesserung des Endpunkts Patientensymptome (12 Studien) oder der Veränderung der Behandlungsdauer für die jeweiligen Beschwerden (7 Studien) zusammenfasste, nicht eindeutig gezeigt werden. Änderungen der medikamentösen Therapie oder bezüglich Überweisungen an Spezialisten für eine weiterführende Therapie konnten nicht analysiert werden, weil nur 2 Studien davon berichteten. Ebenso wurden gesundheitsbezogene Lebensqualität, soziale Funktionsfähigkeit, unerwünschte Ereignisse und Kosten in sehr wenigen Studien berichtet.
Was sollte als Nächstes passieren?
Mehr Forschung von besserer Qualität ist nötig, vor allem in der Grundversorgung, wo die meisten CMHDs behandelt werden. In die Studien sollten Menschen mit eingeschlossen werden, die entweder mit Medikamenten oder mit Psychotherapie behandelt werden und sie sollten länger als sechs Monate lang beobachtet werden. Ebenso wie Symptome und Behandlungsdauer sollten Studien auch mögliche Schäden, Lebensqualität, soziale Fähigkeiten und die Kosten der Beobachtung messen.
Authors' conclusions
Summary of findings
| Feedback of PROM scores for routine monitoring of common mental health disorders | |||||
| Patient or population: People with common mental health disorders1 Intervention: Feedback of PROM scores to clinician, or both clinician and patient Comparator: No feedback of PROM scores | |||||
| Outcomes and length of follow‐up | Illustrative risk | Number of participants | Quality of the evidence | Comments | |
| Assumed risk (range of means in no‐feedback groups) | Relative effect (95% CI) in feedback groups | ||||
| Mean improvement in symptom scores Follow‐up: 1‐6 months2 | Mean scores in no‐feedback groups ranged from 51.8 to 101.5 points for OQ‐45 and from 23.8 to 29.5 points for ORS. Standard deviations ranged from 17.8 to 28.6 points for OQ‐45 and from 7.1 to 9.6 points for ORS | Standard mean difference in symptom scores at end of study in feedback groups was 0.07 standard deviations lower | 3696 | ⊕⊕⊝⊝ | Neither study in the primary care setting used the OQ‐45 or ORS PROMs, and so could not be included in this meta‐analysis |
| Health‐related quality of life Follow‐up: 1‐5 months2 Medical Outcomes Study (SF‐12) physical and mental subscales). Scale from 0‐100 Follow‐up: 0‐1 year | Study results could not be combined in a meta‐analysis as data were not available in an appropriate format Mathias 1994 reported no significant differences between feedback and control groups on all nine domains of the SF‐36 Scheidt 2012 reported no significant differences between feedback and no‐feedback groups in physical or mental sub‐scale scores | 583 587 (1 study) | ⊕⊕⊕⊝ moderate7 | ||
| Adverse events Follow‐up: 6 months | Chang 2012 reported no immediate suicide risk across both feedback and no‐feedback groups combined. Number per group not given | 642 | ⊕⊕⊕⊝ moderate7 | ||
| Social functioning Follow‐up: 0‐1 year2 | Data for the social functioning subscale of the OQ‐45 were considered separately in Hansson 2013 and no difference was found | 262 (1 study) | ⊕⊕⊝⊝ low9 | ||
| Costs | Not estimable | 0 (0 studies) | No study assessed the impact of the intervention on direct or indirect costs | ||
| Changes in the management of CMHDs Changes in drug therapy and referrals for specialist care Follow‐up: 1‐6 months2 | Study results could not be combined in a meta‐analysis as data were not available in an appropriate format Chang 2012 and Mathias 1994 both reported no significant differences in changes in drug therapy between study arms Mathias 1994 reported mental health referrals were significantly more likely in the feedback group (OR 1.73, 95% CI 1.11 to 2.70) | 1215 | ⊕⊕⊕⊝ moderate7 | ||
| Changes in the management of CMHDs Follow‐up: 1‐6 months2 | Mean in no‐feedback groups ranged from 3.7 to 33.5 treatment sessions | Mean difference in number of treatment sessions in feedback groups was 0.02 lower | 2608 | ⊕⊕⊝⊝ | Post‐hoc analysis. Changes in medication and referrals for additional therapy were not assessed by any of these studies |
| CI: Confidence interval | |||||
| GRADE Working Group grades of evidence | |||||
| 1Studies were included if the majority of people diagnosed had CMHDs and no more than 10% had diagnoses of psychotic disorders, learning difficulties, dementia, substance misuse, or eating disorders 2Duration of therapy was variable in all studies and determined by the clinician or the patient, or both 6Downgraded two levels due to risk of bias (all included studies were judged at high risk of bias in at least two domains, in particular blinding of participants and outcome assessment, and attrition), and indirectness (although symptom scores were compared between feedback and non‐feedback groups, wider social functioning and quality‐of‐life measurements were not assessed in nearly all studies) 7Downgraded one level due to risk of bias (judged at high risk of bias in at least two domains, in particular blinding of participants and outcome assessment, and attrition) 8Number of PHQ‐9 questionnaires which contained reports of self‐harming thoughts 9Downgraded two levels due to risk of bias and imprecision, as total participant numbers were less than 400 10Downgraded two levels due to risk of bias and for imprecision: estimate of effect includes no effect and incurs very wide confidence intervals | |||||
Background
Description of the condition
Common mental health disorders (CMHDs) are prevalent, often very disabling and very costly. They include depression (including major depression, dysthymia and minor or mild depression); mixed anxiety and depression; and specific anxiety disorders, namely generalised anxiety disorder (GAD), phobias, obsessive‐compulsive disorder (OCD), panic disorder and post‐traumatic stress disorder (PTSD) (McManus 2009). Katon and Schulberg estimated in 1992 that depression fulfilling the criteria for major depression in the American Psychiatric Association Diagnostic and Statistical Manual, 4th edition (DSM‐IV) (APA 2000) occurred in 2% to 4% of people in the community, 5% to 10% of primary care patients, and 10% to 14% of medical inpatients; but in each setting there were two to three times as many people with depressive symptoms that were short of the major depression criteria (Katon 1992). Prevalence rates of major depression of 13.9% in women and 8.5% in men, and of anxiety disorders of 10% and 5% respectively, have been found in family practice attendees across Europe (King 2008). The estimated one‐week prevalence of CMHDs among adults in England in 2007, according to the criteria of the World Health Organization's International Classification of Diseases (ICD‐10) (WHO 1992) was found to be 17.6%, including mixed anxiety and depression in 9.7%; GAD in 4.7%; depressive episode in 2.6%; phobia in 2.6%; OCD in 1.3%; and panic disorder in 1.2% (McManus 2009). In the US National Comorbidity Survey, lifetime prevalence estimates were 16.6% for DSM‐IV major depression; 6.8% for PTSD; 5.7% for GAD; 4.7% for panic disorder; 2.5% for dysthymia; 1.6% for OCD; and 1.4% for agoraphobia (Kessler 2005).
Depression is often chronic and relapsing, resulting in high levels of disability and poor quality of life (Wells 1989), generally high levels of health service use and associated economic costs (Simon 1997), and death from suicide in between 2% and 8% of cases (Bostwick 2000). Major depressive disorder appears to be increasing in prevalence (Compton 2006) and in the Global Burden of Disease Study 2010 (Murray 2010) has moved up to 11th from 15th in the ranking of disorders according to burden in terms of disability adjusted life years (a 37% increase), becoming the second leading cause of years lived with disability, due to population growth and ageing (Ferrari 2013).
The King’s Fund estimated that in the UK 1.45 million people would have depression by 2026, and the total cost to the nation would exceed GBP 12 billion per year, including prescriptions, inpatient and outpatient care, supported accommodation, social services and lost employment (McCrone 2008). The total medical and productivity costs per person with any anxiety disorder were estimated to be around USD 6500 in the USA in 1999 (Marciniak 2004), and across Europe the annual costs of anxiety disorders, including health service costs, welfare benefits and lost productivity, were estimated to exceed USD 40 billion in 2004 (Andlin‐Sobocki 2005).
Depression is usually treated in primary care with selective serotonin reuptake inhibitor (SSRI) antidepressant drugs (in around 80% of cases), psychological treatments (in around 20%), or both (Kendrick 2009); and in one‐third to one‐half of people with major depression, the symptoms persist over a six to 12‐month period (Gilchrist 2007; Katon 1992). Evidence‐based guidelines recommend psychological treatments such as cognitive‐behaviour therapy (CBT) as first‐line treatment for anxiety disorders (NICE 2011a) but SSRIs are also frequently prescribed for their treatment, often because psychological treatments are not available. It is recommended that people prescribed antidepressants are seen for regular follow‐up during treatment. For example, the UK National Institute for Health and Care Excellence (NICE) 2009 guideline on the management of depression in adults recommended that people started on antidepressants who were not considered to be at increased risk of suicide should normally be seen after two weeks, then at intervals of two to four weeks in the first three months, and then at longer intervals if their response to treatment was good (NICE 2009). At each visit clinicians were recommended to evaluate response (symptoms and functioning), adherence to treatment, drug side‐effects and suicide risk (NICE 2009). This evaluation is usually based on clinical judgement alone, but in recent years clinicians have been advised to consider using patient reported outcome measures (PROMs) to augment their clinical judgement. NICE guidance states all staff carrying out the assessment of common mental health disorders should be competent in the use of formal assessment measures and routine outcome measures (NICE 2011a).
Description of the intervention
PROMs assess patients’ experiences of their symptoms, their functional status and their health‐related quality of life. So they can help to determine the outcome of care in terms of these aspects from the patient’s perspective as an expert in the lived experience of their own health. PROMs are different to measures of patients’ experience of, or satisfaction with, the care they receive (Black 2013). PROMs are often self‐report measures that should therefore be free of observer rating bias, but they can also be interview‐based measures that involve the interviewer in interpreting the patients' responses to questions.
The treatment of CMHDs has been augmented in a number of studies by administering PROMs measuring symptoms of depression or anxiety, social functioning or health‐related quality of life, and feeding the results back to the treating clinician or both the treating clinician and the patient. Feedback of the results is the essential element. The intervention will usually include education of the clinician, or both the clinician and patient, about the measures used and their interpretation. It may or may not also include specific instructions on action to take in light of the results, which may be in the form of an algorithm.
How the intervention might work
Carlier 2012 identifies two main theories concerning the links between the use of PROMs, the process of care and outcomes for patients, Feedback Intervention Theory (FIT) and Therapeutic Assessment (TA). FIT suggests that feedback of the results of PROMs to healthcare professionals influences them to adjust treatment or refer for alternative interventions, improving care when measured against best practice guidelines; while TA focuses on the potential therapeutic effects of feeding back the test results to patients.
Greenhalgh 2005 pointed out that feedback to the clinician may initiate specific changes in management, including ordering further tests, referring to other professionals, changing treatments, and giving advice and education to the patient on better control or management of the problem. Feeding the results back to the patient as well as to the clinician can potentially further improve the process of care, as patients often like to be more involved in their own care, which may be beneficial in itself. This may promote better communication and a greater understanding of the patient's personal circumstances, enabling joint decision‐making between clinician and patient, increasing concordance and patient adherence to treatment through agreeing shared goals, and increasing patient satisfaction, all of which in turn can potentially improve the outcome for the patient.
Observational studies suggest that general practitioner (GP) treatment decisions (to prescribe antidepressants, to subsequently change prescriptions, or refer patients for specialist treatment) might be influenced by the results of patient‐completed depression symptom questionnaires at diagnosis (Kendrick 2009) and follow‐up (Moore 2012), in line with the predictions of FIT. A trial of feeding back depression symptom questionnaire scores to primary care physicians and patients in the USA led to increased rates of response to treatment and remission among patients in the intervention arm (Yeung 2012) although this was despite an apparent lack of significant changes in the physicians' management of the patients' depression (Chang 2012). The authors suggested that frequent symptom measurement might have increased patients' symptom awareness and their ability to report relevant symptoms to their physicians, or made them feel more supported, contributing to a lower medication discontinuation rate in the intervention group. Qualitative research suggests that patients with depression do value the use of symptom questionnaires to assess their condition (Dowrick 2009) and the effectiveness of their treatment (Malpass 2010). It might be that if patients feel that they have been assessed more thoroughly and become more involved in the care of their disorder through the completion of PROMs, together with feedback of the significance of the results, this can help them to improve more quickly even in the absence of significant changes in management, in line with the predictions of TA.
Why it is important to do this review
The use of PROMs has been promoted in recent years as a way for patients to become more involved in their own care and to help health professionals make better decisions about their treatments (Black 2013; Black 2015; Fitzpatrick 2009).
In particular, the use of PROMs in depression has been promoted in important policy pronouncements. The US Federal Health Resources and Services Administration (HRSA) Collaborative on Depression included quality standards for the proportion of patients assessed using the self‐complete Patient Health Questionnaire (PHQ‐9) depression symptom measure (Spitzer 1999) at diagnosis and follow‐up (HRSA 2005). The NICE 2009 depression guideline recommended that clinicians should consider using a validated measure (for example for symptoms, functions and disability) to inform and evaluate treatment (NICE 2009). The subsequent NICE quality standard on assessment of depression recommended that practitioners delivering interventions for people with depression should record the results of validated health outcome measures at each treatment contact and use the findings to adjust their delivery of interventions (NICE 2011b). In 2009 a performance indicator was added to the UK National Health Service (NHS) GP pay for performance scheme (the Quality and Outcomes Framework or QOF), financially incentivising the follow‐up assessment of depression with symptom questionnaires five to 12 weeks after diagnosis (BMA & NHS Employers 2009). The UK NHS Increasing Access to Psychological Therapies (IAPT) programme, extending the provision of psychological treatments for CMHDs nationwide, adopted an information standard with an instruction to record PROMs at every visit, including the PHQ‐9 for depression, the self‐complete Generalised Anxiety Disorder questionnaire (GAD‐7) for anxiety (Spitzer 2006), and the Work and Social Adjustment Scale (WSAS, Mundt 2002) for social functioning (IAPT 2011).
The potential for PROMs to improve the care and self‐care of CMHDs cannot be assumed however. The administration of symptom, social functioning, or quality‐of‐life questionnaires to each and every patient with a CMHD adds up to a significant investment of resources in terms of professionals' time given the high numbers of patients with CMHDs, especially in primary care. Following the introduction of the QOF performance indicator financially incentivising the follow‐up assessment of depression with symptom questionnaires, GPs in the UK reported completing more than 1.1 million follow‐up assessments between April 2009 and March 2013 (74% of 1.5 million eligible cases identified in those five years) (QOF Database 2013). The cost to the NHS of those assessments added up to more than GBP 25 million per year in terms of GP time and the incentive payments. Therefore, even such relatively simple quality improvement strategies should be supported by evidence of clinical benefit and cost‐effectiveness.
There have been a number of previous systematic reviews related to this question including studies in different sectors of health care: one of studies in non‐psychiatric settings (Gilbody 2002); one of studies in clinical psychology practice (Lambert 2003), updated in 2010 (Shimokawa 2010); two combining studies in multidisciplinary mental health care (which we previously referred to as 'specialist psychiatric practice', see section on Differences between protocol and review) and clinical psychology practice (Davidson 2014; Knaup 2009); and one limited to studies in primary care (Shaw 2013). The review by Gilbody and colleagues failed to show an impact of patient‐centred outcome instruments assessing patient needs or measuring quality of life in non‐psychiatric settings (Gilbody 2002). However, Knaup and colleagues' systematic review of studies in specialist psychological and multidisciplinary mental health care settings, which included the studies previously reviewed by Lambert and colleagues (Lambert 2003), was more positive, demonstrating benefits of routine outcome measurement for a range of mental health problems (Knaup 2009). Outcomes were found to be improved with an effect size of between 0.1 and 0.3 standard deviations, being improved more when patients were involved in rating their own problems and received feedback on their progress in addition to feedback to the practitioner (Knaup 2009). However, this review included studies of people with more severe mental illnesses as well as CMHDs. Conversely, the 2013 review (Shaw 2013) had a narrow focus as it was limited to studies of the assessment and monitoring of depression in primary care using questionnaires recommended in the NHS GP contract QOF, namely the PHQ‐9, Hospital Anxiety and Depression Scale (HADS) (Zigmond 1983) and Beck Depression Inventory (BDI) (Beck 1961) or BDI‐II (Beck 1996). Other systematic reviews and meta‐analyses have included studies of the use of PROMs as screening or diagnostic tools together with studies of their use as follow‐up monitoring measures (Carlier 2012; Poston 2010) or have included studies of the use of PROMs in the management of physical disorders together with studies in mental health care (Boyce 2013; Marshall 2006; Valdera 2008). One recent systematic review included only studies which evaluated feeding back the results of PROMs in terms of changes in the particular PROM score rather than other relevant outcome measures (Boyce 2013).
There has been no systematic review of the use of PROMs in the routine outcome monitoring of CMHDs in adults across primary care, psychological therapy, and multidisciplinary mental health care settings. Given the high prevalence of CMHDs, the current policy drive promoting routine outcome monitoring across these settings, and the likely significant cost of such widespread monitoring of highly prevalent conditions, there is an urgent need for evidence to guide further developments in policy and clinical practice. We therefore aimed to conduct a comprehensive, up‐to‐date systematic review of the use of PROMs in CMHDs, including studies across primary care, multidisciplinary mental health care, and psychological therapy settings. We aimed to include measures of social functioning and health‐related quality of life (QoL) as well as measures of symptoms of depression and anxiety, because functioning and QoL measures may also influence clinician treatment decisions or patient involvement in their own care, or both, and therefore outcomes for patients.
PROMs can be used as a tool to identify patients with CMHDs whose problems would otherwise be missed, but in this review we were not concerned with the use of PROMs as a screening tool. This was the subject of a previous review, Gilbody 2008. In this review we were concerned with the use of PROMS in monitoring patients' progress and response to treatment, which requires feedback and assessment of the results at follow‐up, after a period of treatment, rather than screening or assessment only before diagnosis or at the point of diagnosis.
We conducted this review according to the methods set out in the protocol (Kendrick 2014).
Objectives
To assess the effects of routine measurement and feedback of the results of PROMs during the management of CMHDs in 1) improving the outcome of CMHDs; and 2) in changing the management of CMHDs.
Methods
Criteria for considering studies for this review
Types of studies
We included randomised controlled trials (RCTs), including cluster RCTs and RCTs randomised at the level of individual participants. We excluded non‐randomised trials.
We planned to include cluster trials where clusters were allocated to intervention or control arms using a quasi‐randomised method, such as minimisation, to avoid significant imbalance between arms arising by chance when the number of clusters is relatively small, but planned to exclude quasi‐randomised trials where allocation was at the level of individual participants. We planned to exclude cross‐over trials because of the very high risk of carry‐over of the intervention into the control arm after participating clinicians or patients cross over. We also planned to exclude uncontrolled before and after trials, and observational studies. However, none of these types of studies was identified.
Types of participants
Participant characteristics
We selected studies which included participants with common mental health disorders (CMHDs) aged 18 years and over, of both genders and all ethnic groups. We excluded studies in child and adolescent treatment settings, as the diagnostic categories included within the group recognised as CMHDs are limited to adults, and in addition the presence of a parent or other carer accompanying a child or adolescent patient complicates the issues of who is providing responses to PROMs administered to monitor the outcome of treatment, and to whom feedback of the results is given.
Diagnosis
We included adult patients with any CMHD, including both those with formal diagnoses according to the criteria of the DSM (APA 2000) or ICD (WHO 1992), and those diagnosed through clinical assessment only, unaided by formal reference to specific diagnostic criteria. The specific disorders included were:
-
depression (including major depression, dysthymia, and minor or mild depression);
-
mixed anxiety and depression;
-
generalised anxiety disorder (GAD);
-
phobias;
-
obsessive‐compulsive disorder (OCD);
-
panic disorder;
-
post‐traumatic stress disorder (PTSD);
-
adjustment reaction.
We included studies in which the diagnoses of the majority of participants were reported as CMHDs, even if a proportion of participants were not given a specific diagnosis, or were reported as having relationship or interpersonal difficulties, 'somatoform disorders', 'other' diagnoses not further specified, or 'administrative codes'. This was a change from the protocol as we planned originally to include only studies with participants specifically diagnosed with one of the disorders listed above, but after discussion within the review study group we decided to include these studies in order to be able to include studies which had a majority of participants diagnosed with CMHDs (see section on Differences between protocol and review).
We excluded studies with more than 10% of patients diagnosed specifically with psychoses, substance use disorders, learning disorders or dementia. We also excluded studies with more than 10% of participants diagnosed with eating disorders, as they are a separate group of disorders not usually included within the group recognised as CMHDs, and the PROMs used for eating disorders are less generic and specifically concentrate on eating habits and weight control measures. This was also a change from the protocol as we planned to exclude studies with any participants at all in these categories, but again, after discussion within the review study group we decided to include studies with fewer than 10% of participants with these diagnoses, in order once again to be able to include studies which had a majority of participants with CMHDs (see section on Differences between protocol and review).
Where studies did not report the diagnoses of participants, we attempted to contact the authors to request information on the participant diagnoses, and whether they would have met the review inclusion and exclusion criteria. This was an addition to the protocol (see section on Differences between protocol and review).
We carried out sensitivity analyses omitting studies which did not report specific diagnoses of CMHDs for 20% or more of their participants, to determine whether these decisions affected the findings.This was an addition to the protocol agreed once again after discussion within the review study group (see section on Differences between protocol and review).
Co‐morbidities
Participants diagnosed with or without co‐morbid physical illnesses were included to ensure as representative a sample as possible.
Setting
Three settings were included: primary care (where the clinicians were all primary care physicians and available treatments post‐assessment included either drug therapy or referral for psychological therapy); multidisciplinary mental health care (where the clinicians included psychiatrists, psychologists, mental health social workers or mental health nurses, and available treatments included drugs, psychological therapies, and physical treatments); and psychological therapies (where the clinicians were psychologists, social workers or nurses and available treatments were all psychological).
Subset data
We planned to include trials that provided data on a relevant subset of their participants, for example studies which compared usual care in one arm with routine outcome monitoring in another, even if there was a third arm with a more complex intervention, but we did not identify any such trials. We also planned to include trials that included a subset of participants who met our criteria for the review, for example in terms of the types of disorder or age range, if the data for those participants could be extracted separately from the rest of the trial sample, but again we did not identify any such trials.
Types of interventions
Experimental intervention
The intervention consisted of augmenting the assessment and management of CMHDs by both of the following.
-
Measuring patient reported outcomes (PROMs), including self‐complete or administered measures of:
-
depressive symptoms, for example the PHQ‐9 (Spitzer 1999). We planned to include the HADS depression subscale (HAD‐D) (Zigmond 1983); BDI (Beck 1961) and BDI‐II (Beck 1996), but found no relevant studies which used them as PROMs;
-
anxiety symptoms, for example the Beck Anxiety Inventory (BAI) (Wetherall 2005). We planned to include the GAD‐7 (Spitzer 2006) but no trials used it;
-
health‐related QoL, for example with the Medical Outcomes Study Short Form SF‐36 (Wells 1989) or SF‐12 (Ware 1996). We planned to include the EuroQol five item EQ‐5D questionnaire (Dolan 1997) but no trials used it;
-
symptoms, individual functioning, and social functioning as composite measures, for example the 45‐item Outcomes Questionnaire (OQ‐45) (Lambert 2004), and the Outcome Rating Scale (ORS) (Miller 2003). We planned to include the Clinical Outcomes in Routine Evaluation Outcome Measure (CORE‐OM) (Barkham 2006) but no trials used it
-
-
Feeding the results back to the treating clinician, to both the clinician and the patient, or to the patient only.
We also planned to include studies using the following as PROMs but found no relevant studies:
-
measures of depression and anxiety combined, for example the self‐complete General Health Questionnaire (GHQ‐28) (Goldberg 1972) or the administered Mini‐International Neuropsychiatric Interview (MINI) (Sheehan 1998); and
-
measures of social functioning, for example the WSAS (Mundt 2002) or the Social Adjustment Scale (SAS) (Cooper 1982)).
Comparator intervention
The comparator was usual care for CMHDs without feeding back the results of PROMs. Routine care includes usual patient‐clinician interaction with non‐standardised history‐taking, investigation, referral, intervention and follow‐up. Trials were excluded if the comparator interventions involved the use of feedback of the results of PROMs as a clinical tool to inform management of the participants. Measures of depression, anxiety, social functioning and quality of life may have been assessed independently by researchers in both the intervention and control conditions to determine the effects of the intervention, but the active component, which was the feeding back of this information to the clinician, or to the patient, or to both clinician and patient, had to occur only in the intervention arm.
Excluded interventions
We excluded studies where the intervention arm was subject to additional components over and above the feedback of PROM results, including pharmacological or psychological treatments that were not available to both the intervention and control groups. A number of more complex interventions have been advocated to improve the quality of care of people with CMHDs including case management (Simon 2004) and collaborative care (Archer 2012), and these usually include feeding back the results of PROMs at initial assessment and follow‐up to inform treatment. However, this review was limited to the effects of feedback of the results of PROMs alone, rather than their use as a component of complex interventions which also enhanced the process of care through case management, collaborative care, active outreach or other systems or processes over and above usual care. It would not have been possible to distinguish the effects of outcome monitoring from other active components in such studies.
Types of outcome measures
Studies that met the above inclusion criteria were included regardless of whether they reported on the following outcomes.
Primary outcomes
1. Mean improvement in symptom scores
Mean improvement in symptom scores (and standardised effect size) from baseline to follow‐up on a symptom‐specific scale, which was either:
-
an interviewer‐rated measure; or
-
a self‐complete questionnaire measure.
Measures used included:
-
interviewer‐rated measures of depression and anxiety including the Diagnostic Interview Schedule (DIS) for DSM‐III disorders (Robins 1981); and
-
self‐complete measures including the PHQ‐9 (Spitzer 1999); BDI (Beck 1961) and BDI‐II (Beck 1996) for depression; the BAI (Wetherall 2005) for anxiety; and the Hopkins symptom checklist SCL‐90 (Derogatis 1974; Derogatis 1983) for both anxiety and depression.
We also planned to include, but found no relevant studies which used the following as primary outcome measures:
-
the interviewer‐rated Hamilton Depression Rating Scale (HDRS or HAMD) (Hamilton 1960); Montgomery‐Asberg Depression Rating Scale (MADRS) (Montgomery 1979); Structured Clinical Interview for DSM‐IV disorders (SCID) (First 1997); and the interviewer‐rated version of the Quick Inventory of Depressive Symptomatology (QIDS) (Trivedi 2004);
-
the self‐complete Community Epidemiologic Survey Depression (CES‐D) scale for DSM‐III depression (Radloff 1997); Zung depression scale (SDI) (Zung 1965); GAD‐7 anxiety scale (Spitzer 2006); GHQ (Goldberg 1972); HADS (Zigmond 1983); Hopkins symptom checklist (Derogatis 1974; Derogatis 1983); Clinical Interview Schedule, Revised (CIS‐R) for ICD‐10 disorders (Lewis 1992); and the self‐complete version of the Quick Inventory of Depressive Symptomatology (QIDS) (Trivedi 2004).
2. Health‐related quality of life
Health‐related quality of life, assessed using specific measures at baseline and follow‐up, including the SF‐36 (Wells 1989). We also planned to include the EQ‐5D (Dolan 1997) but identified no relevant trials which used it.
3. Adverse events, including:
-
numbers and types of antidepressant drug side‐effects;
-
numbers of incidences of self‐harm, and
-
numbers of suicides.
Secondary outcomes
4. Changes in the management of CMHDs
Changes in the management of CMHDs following administration and feedback of the results of PROMs, including:
-
number of changes in drug prescribing (a new prescription, a change in dose or type of drug, or the ending of a prescription);
-
number of referrals for psychological assessment or treatment;
-
number of referrals for psychiatric assessment or treatment.
These are relevant secondary outcomes, as they indicate more proactive care, which might lead to more positive outcomes, although a change in management cannot by itself be regarded as necessarily a positive outcome.
5. Social functioning
Social functioning assessed using specific measures at baseline and follow‐up, for example the WSAS (Mundt 2002). We also planned to include the SAS (Cooper 1982) but identified no relevant trials which used it.
6. Costs, including:
-
the direct costs of administering PROMs and delivering feedback of the results;
-
costs to the health service, including consultations, prescriptions, outpatient attendances and hospital admissions; and
-
societal costs, including costs to the patient and to society in terms of loss of employment and costs of sickness benefits.
Timing of outcome assessment
We planned to divide the reporting of research outcomes into:
-
short‐term, up to six months after baseline assessment; and
-
long‐term, beyond six months.
Hierarchy of outcome measures
We planned to select self‐complete research outcome measures in preference to interviewer‐rated measures of symptoms, social functioning or health‐related quality of life as they are less prone to detection bias due to unblinding of the researcher assessing the outcome. In completing an interviewer‐rated measure the researcher filters all patient reported responses, while for self‐complete measures only those responses which the patient chooses to discuss with the researcher can be influenced by an unblinded researcher.
Search methods for identification of studies
The Cochrane Depression, Anxiety and Neurosis Review Group's Specialised Register (CCDANCTR)
The Cochrane Depression, Anxiety and Neurosis Group (CCDAN) maintain two clinical trials registers at their editorial base in Bristol, UK: a references register and a studies‐based register. The CCDANCTR‐References Register contains over 39,000 reports of RCTs in depression, anxiety and neurosis. Approximately 50% of these references have been tagged to individual, coded trials. The coded trials are held in the CCDANCTR‐Studies Register and records are linked between the two registers through the use of unique Study ID tags. Coding of trials is based on the EU‐Psi coding manual using a controlled vocabulary (please contact the CCDAN Trials Search Co‐ordinator for further details). Reports of trials for inclusion in the Group's registers are collated from routine (weekly), generic searches of Ovid MEDLINE (1950 ‐), EMBASE (1974 ‐) and PsycINFO (1967 ‐); quarterly searches of the Cochrane Central Register of Controlled Trials (CENTRAL); and review specific searches of additional databases. Reports of trials are also sourced from international trials registers through the World Health Organization's trials portal (the Clinical Trials Registry Platform (ICTRP)) and the handsearching of key journals, conference proceedings and other (non‐Cochrane) systematic reviews and meta‐analyses.
Details of CCDAN's generic search strategies (used to identify RCTs) can be found on the Group's website.
Electronic searches
1. The CCDANCTR (References and Studies Register) was initially searched to 30 May 2014 using the following terms:
#1 ("affective disorder*" or “common mental disorder*” or “mental health” or "acute stress" or adjustment or anxi* or compulsi* or obsess* or OCD or depressi* or dysthymi* or neurosis or neuroses or neurotic or panic or *phobi* or PTSD or posttrauma* or "post trauma*" or “stress disorder*” or trauma* or psychotrauma*):ti,ab,kw,ky,emt,mh,mc
#2 PROMS
#3 (“patient reported outcome*” or “patient reported assessment*” or “patient reported symptom*”)
#4 “patient outcome*”
#5 ((patient* or client* or tailored) NEAR2 feedback)
#6 (patient* NEXT ("self assess*" or "self report" or "self monitor*"))
#7 (patient* NEAR2 progress*)
#8 "client report*"
#9 ((active or routine* or regular*) NEAR2 (feedback or measurement* or monitor*))
#10 (monitor* and feedback*)
#11 (“feedback to” or "feed back to" or "fed back to"):ab
#12 ((symptom* or treatment) NEXT monitor*)
#13 (monitor* NEAR2 (“common mental disorder*” or anxi* or compulsi* or obsess* or OCD or depressi* or neurosis or neuroses or neurotic or panic or *phobi* or PTSD or posttrauma* or "post trauma*" or "acute stress" or “stress disorder*” or trauma*))
#14 ((follow‐up* or "follow up*") and assess*):ti
#15 (needs NEAR3 assess*)
#16 (outcome* NEAR (clinical or feedback or manag* or monitor*)):ti
#17 “severity questionnaire*”
#18 severity:ti,kw,ky and (assess* or measure* or outcome* or questionnaire* or score*):ti
#19 (“case management” or “enhanced care”)
#20 (#2 or #3 or #4 or #5 or #6 or #7 or #8 or #9 or #10 or #11 or #12 or #13 or #14 or #15 or #16 or #17 or #18 or #19)
#21 (#1 and #20)
[Key. ab:abstract; emt:EMTREE headings; kw:CRG keywords; ky:other keywords; mc:MesH check words; mh:MeSH headings]
Due to the nature of the intervention (patient reported outcome measures) the search strategy was designed to favour specificity (precision) over sensitivity (recall of all potentially relevant reports). A sensitive search would retrieve too much noise as most of the measures and questionnaires under review are much more frequently used to assess symptom severity or quality of life as research outcomes in treatment trials in patients with CMHDs than as PROMs used for clinical assessment.
2. Complementary searches were conducted on the following bibliographic databases using relevant subject headings (controlled vocabularies) and search syntax that were appropriate to each resource. Searches initially performed to 5 June 2014:
(i) Ovid PsycINFO (all years)
Although PsycINFO is routinely searched to inform the CCDANCTR, we conducted an additional search of this database to increase the sensitivity of our search methods, adding wait‐list control and treatment‐/care‐as‐usual to CCDAN's standard RCT filter. The search strategy is described in Appendix 1.
(ii) PROM Bibliography database (all years to 2005)
The PROM Bibliography was searched for RCTs in mental health. This database, which is available through The Patient‐Reported Outcomes Measurement Group at the University of Oxford, was first published in 2002 with funding from the Department of Health (DH). It was further developed with DH funding to 2005 and contains over 16,000 records relating to patient reported outcome measures.
(iii) Web of Science (WoS): Science Citation Index (cited reference search, all years as appropriate)
3. International trial registries were also searched on 19 February 2015 and 9 April 2015 via the World Health Organization's trials portal (ICTRP) and ClinicalTrials.gov to identify unpublished or ongoing studies. We searched for depression OR depressive OR mental OR psychiatric OR anxiety OR PTSD OR phobia OR OCD AND feedback.
There were no restrictions on date, language or publication status applied to the searches.
4. Update searches 2015
An update search was performed on 18 May 2015 to identify additional RCTs eligible for inclusion. At this time we thought it appropriate to validate the 2014 searches by checking the (a) the provenance of included studies (to date) and (b) information contained in the title,abstract and subject heading fields of study reports in MEDLINE, EMBASE and PsycINFO. This exercise revealed that eight of the eleven included studies (>70%) were only identified from screening reference lists or from the Web of Science citation search and four of these studies made no mention of the patients' mental health condition. The searches were overhauled and the PsycINFO and CCDANCTR databases re‐searched all years to 18 May 2015, together with a search of the Cochrane Library (Appendix 2). A further citation search of WoS was also conducted, to 27 May 2015.
5. Update searches 2016
In compliance with MECIR conduct standard 37 we ran an update search within 12 months of publication (on 25 May 2016), including the following databases: PsycINFO, CCDANCTR, CENTRAL, Web of Science, and the ICTRP/ClinicalTrials.gov international trial registries. These results have not yet been incorporated into the review.
Searching other resources
Grey literature
Google Scholar (top 100 hits) and Google.com were searched (verbatim) for: "Patient Reported Outcome Measures" and "mental health" and (randomised or randomized). Search results were screened for relevant reports and reviews.
Reference lists and correspondence
We screened reference lists (of trial reports and systematic reviews) to identify additional studies missed from the original electronic searches (including unpublished or in‐press citations); used the related articles feature in PubMed; and contacted other experts and trialists in the field for information on unpublished or ongoing studies, or to request additional trial data. 'Patient reported outcome measures' and 'PROMs' are relatively recently adopted terms in the literature. For earlier studies, where the terminology used may be ambiguous, we had to rely more on these informal methods of discovery.
Data collection and analysis
Selection of studies
Two review authors (TK and ME‐G) independently screened titles and abstracts for inclusion of all the potential studies identified as a result of the search, coded as 'retrieve' (eligible or potentially eligible or unclear) or 'do not retrieve'. We resolved disagreements through discussion and consultation with a third author (MM). We retrieved the full‐text study reports or publications and the same two review authors independently screened the full texts, identified studies for inclusion, and identified and recorded reasons for exclusion of the ineligible studies. Again, disagreements were resolved through discussion and consultation with the third author MM. We excluded duplicate records and collated multiple reports that related to the same study so that each study rather than each report became the unit of interest in the review. We recorded the selection process in sufficient detail to complete a PRISMA flow diagram (Moher 2009) and 'Characteristics of excluded studies' table.
Data extraction and management
We designed and used a data collection form which was piloted on one study in the review to extract study characteristics and outcome data. Five review authors (TK, ME‐G, AB, LA, ALB) independently extracted study characteristics and outcome data from the included studies. We extracted the following study characteristics.
-
Methods: study design (cluster or individual randomisation), total duration of study, number of study centres and location, study setting, withdrawals, and dates of study.
-
Participants: n, mean age, age range, gender, severity of condition, diagnostic criteria (clinical only, DSM or ICD, etc.), inclusion criteria, exclusion criteria, and co‐morbidities.
-
Interventions: intervention including the specific instrument(s) used and whether the results were fed back to the treating clinician only or also to the participant; whether education about interpretation and an algorithm were also provided; and details of treatment as usual provided to the comparison group.
-
Outcomes: primary and secondary outcomes specified and collected, and time points reported.
-
Notes: funding for trial, and notable conflicts of interest of trial authors.
We noted in the 'Characteristics of included studies' table if outcome data were not reported in a usable way. We resolved disagreements by consensus and also by involving a third person (MM). Two review authors (TK, ME‐G) transferred data into Review Manager (RevMan) (RevMan 2014), and double‐checked that data were entered correctly by comparing the data presented in the systematic review with the study reports. Another two review authors (BS, AG) spot checked the accuracy of data extracted, against the original study reports.
Main comparison
-
Treatment informed by feedback of patient reported outcome measures compared with treatment as usual.
Assessment of risk of bias in included studies
Two review authors (TK and ME‐G) independently assessed the risk of bias for each study using the criteria outlined in the Cochrane Handbook for Systematic Reviews of Interventions (Higgins 2011). We resolved any disagreements by discussion and by involving other authors (MM, BS, RC, SG). We assessed the risk of bias according to the following domains:
-
Random sequence generation.
-
Allocation concealment.
-
Blinding of participants and clinicians (performance bias, which will be high due to the nature of the intervention).
-
Blinding of researchers conducting outcome assessments (detection bias).
-
Incomplete outcome data.
-
Selective outcome reporting.
-
Other bias.
We judged each potential source of bias as high, low or unclear and provided supporting quotations from the study report where available, together with a justification for our judgment in the 'Risk of bias' table. We summarised the risk of bias judgements across different studies for each of the domains listed. We considered blinding separately for different key outcomes where necessary. Where information on risk of bias related to correspondence with a trialist, we noted this in the 'Risk of bias' table.
When considering treatment effects, we took into account the risk of bias for the studies that contributed to that outcome.
Measures of treatment effect
Continuous data
We calculated mean differences (MD) and the associated 95% confidence interval (CI) for continuous outcomes where there was a common measure across studies, and standardised mean differences (SMD) and the associated 95% CI where different scales were used to measure the same underlying construct. We entered the data presented as a scale with a consistent direction of effect.
Dichotomous data
We carried out a narrative analysis to describe categorical outcomes. See Differences between protocol and review.
Unit of analysis issues
Cluster randomised trials
Clustering by clinician, clinic, practice or service would be the preferred design over randomising individual participants since a clustered design reduces the risk of contamination between arms, as the PROMs are not routinely available in the control settings and are therefore much less likely to be used inadvertently in control patients. However, failure to account for intra‐class correlation in clustered studies is commonly encountered in primary research and leads to a 'unit of analysis' error (Divine 1992) whereby P values are spuriously low, CIs unduly narrow, and statistical significance overestimated, causing type I errors (Bland 1997; Gulliford 1999). For studies that employed a cluster randomisation, we sought evidence that clustering was accounted for by the authors in their analyses.
Studies with multiple treatment groups
Where multiple trial arms were reported in a single trial, we included all relevant arms that compared treatment as usual with routine outcome monitoring.
Where we found three‐armed trials that compared PROMs fed back to the clinician only, versus PROMs fed back to both the clinician and patient, versus treatment as usual, we divided the control group between the two comparisons so as not to use the same data twice, which would constitute a unit of analysis error. However, we also performed a sensitivity analysis excluding any trials with this three‐arm design from the subgroup analysis (see below) to see whether this significantly affected the results of the subgroup analysis.
Dealing with missing data
We contacted investigators in order to verify key study characteristics and obtain missing numerical outcome data, where possible. We documented all correspondence with trialists and report which trialists responded below. (If standard deviations were missing, we planned to calculate them, if possible, from the available information reported (including 95% CIs and P values) or impute standard deviations from similar studies using the same instruments, but in the event we did not need to do this).
Assessment of heterogeneity
Between‐study heterogeneity was assessed using the I2 statistic (Higgins 2003), which describes the percentage of total variation across studies that is due to heterogeneity rather than chance. A rough guide to interpretation is as follows: 0% to 40% might not be important; 30% to 60% may represent moderate heterogeneity; 50% to 90% may represent substantial heterogeneity; and 75% to 100% considerable heterogeneity. We investigated the sources of heterogeneity as described below where the I2 value was greater than 50%. Where I2 was below 50% but the direction and magnitude of treatment effects suggested important heterogeneity, we also investigated the potential sources.
Assessment of reporting biases
We created funnel plots where feasible and where there were sufficient studies (that is 10) (Egger 1997) to investigate possible publication bias. Funnel plot tests for asymmetry were separately conducted in STATA (StataCorp. 2015), using the metabias command.
Data synthesis
We undertook meta‐analyses only where it was meaningful, that is where the PROM feedback interventions, participants and the underlying clinical question were similar enough for pooling to make sense. We pooled change scores as a first preference where these were available, checking assumptions about the approximate normality of data by ensuring that the difference between the mean and lowest or highest possible value divided by the standard deviation was greater than two. Less than two would indicate some skew and less than one would indicate substantial skew. We planned not to attempt pooling for data that were substantially skewed and where the skew could not be reduced by transforming the data. We planned to describe skewed data as medians and interquartile
ranges.
We anticipated significant heterogeneity between studies (I2 value of over 50%) as we were including a range of CMHDs, a range of settings, and both self‐complete and administered outcome measures. Therefore we used a random‐effects model when combining data to minimise the effect of heterogeneity between studies. Where studies were combined which used outcome measures that scored treatment effects in opposite directions, the mean values of one set of studies were multiplied by ‐1 to ensure the scales identified benefited in the same direction, in accordance with section 9.2.3.2 of the Cochrane Handbook (Deeks 2011).
Where cost data were presented and a formal cost‐effectiveness analysis had been undertaken, we planned simply to describe the methods and results. We did not plan to attempt formal statistical pooling of cost data because studies often adopt different perspectives; account for different types of cost data; use different methods of discounting future healthcare costs and benefits; are conducted at different points in time; and are conducted in different countries with varying funding and reimbursement systems, making international comparisons difficult.
Subgroup analysis and investigation of heterogeneity
We planned to conduct the following six subgroup analyses, which should be regarded as exploratory since they are observational and not based on randomised comparisons. We planned to restrict these six subgroup analyses to the three primary outcomes (namely improvement in symptom scores, health‐related quality of life, and adverse effects).
-
Whether the setting of the study (primary care, multidisciplinary mental health services, or psychological therapies) influenced the success of the strategy.
-
Studies in which a formal diagnosis (according to DSM or ICD criteria) was made prior to treatment using a validated assessment, versus studies of participants diagnosed on clinical assessment only, as the formally diagnosed group were likely to be more homogeneous and more alike in their responses to PROMs.
-
Studies of participants aged 18 to 65 years versus those with participants aged over 65 years, as the older age group may have more complex disorders with co‐morbid cognitive changes and it is plausible that recovery follows a different pathway.
-
Studies where feedback of the results of PROMs was given only to the clinician versus studies where feedback was given to both clinician and participant, as the previous review by Knaup 2009 showed a greater effect when patients were also given feedback.
-
Studies where feedback of the results of PROMs was given only to the participating patient versus studies where feedback was given to the clinician only, or to both clinician and patient, if any such studies were identified (we thought this was unlikely given the results of previous systematic reviews of outcome monitoring in mental health, which have not identified any studies of feedback to patients alone).
-
Studies where feedback to the clinician included treatment instructions or an algorithm for actions to be taken for particular results, compared to studies where feedback was limited to the results of the PROM alone, to determine whether treatment recommendations in addition to PROM results influenced the results.
Post‐hoc subgroup analyses
We decided post‐hoc to conduct an additional subgroup analysis, comparing studies involving Michael Lambert, the originator and owner of the OQ‐45 system, with studies not involving him, to explore whether potential benefits of the system were identified in independent evaluations. This was because the OQ‐45 was the PROM used in the large majority of studies in the meta‐analyses, and Michael Lambert was author or co‐author of a significant proportion of those studies (see section on Differences between protocol and review).
We also decided during the course of the review to meta‐analyse results for subgroups of participants within studies who were identified as being at higher or lower risk for treatment failure, which was determined by the trajectory of their initial response to therapy. The low risk group was described as 'on‐track' (OT) for a good clinical response, and the high risk group as 'not on track' (NOT). This was a post‐hoc change to the methods which we agreed due to the fact that several identified studies reported potentially important findings in analyses of outcomes for subgroups of OT and NOT participants. One comparison included only the NOT subgroup, comparing outcomes in terms of symptom scores between feedback and non‐feedback arms. The second comparison included both the OT and NOT subgroups, comparing the number of treatment sessions received between feedback and non‐feedback arms, and including a formal test for subgroup differences to look for evidence of differences between OT and NOT subgroups. This was a further change from the protocol, as the number of treatment sessions was a secondary outcome, and originally we planned to conduct subgroup analyses restricted to the three primary outcomes, namely symptoms, health‐related quality of life, and adverse effects (see section on Differences between protocol and review).
Sensitivity analysis
We planned to conduct the following sensitivity analyses to explore their effects on the results obtained in the review, and to test the robustness of decisions made in the review process:
-
Whether the mode of administration (self‐complete versus clinician‐rated) influenced the success of the strategy, by re‐analysing after removing studies using clinician‐rated PROMs and seeing whether the result was significantly different.
-
Whether cluster randomised studies produced a different result from non‐clustered studies, to see whether possible contamination between arms in non‐clustered designs reduced the difference between arms, by re‐analysing after removing non‐clustered studies.
-
Within cluster RCTs, whether adjustment for unit of analysis error influenced the results, to test the robustness of the results arising from non‐adjusted analyses.
-
Whether the inclusion of quasi‐randomised cluster trials significantly affected the results, by re‐analysing after removing quasi‐randomised cluster trials.
-
Whether losing the data from three‐arm trials that compared PROMS fed back to the clinician only, versus PROMS fed back to both the clinician and patient, versus treatment as usual, made a significant difference to the results of the subgroup analysis (4 above), by excluding such trials from the subgroup analysis.
'Summary of findings' tables
We developed 'Summary of findings' tables to summarise the key findings of the review, for the populations in primary care, multidisciplinary mental health care, and psychological therapy settings. We tabulated the comparisons between PROMs and usual care in terms of effects on participant outcomes including symptoms, social functioning, quality of life and adverse effects; and on the process of care including drug prescriptions and referrals. Decisions on which measurements to incorporate into the 'Summary of findings' table were based on those most relevant to clinical practice, taking into consideration the specific nature of the scale and also the time points at which measurements were made. We used the GRADE criteria to assess the body of evidence for each comparison.
Results
Description of studies
Seventeen studies met our inclusion criteria: Amble 2014; Berking 2006; Chang 2012; De Jong 2012; De Jong 2014; Hansson 2013; Hawkins 2004; Lambert 2001; Mathias 1994; Murphy 2012; Probst 2013; Reese 2009a; Reese 2009b; Scheidt 2012; Simon 2012; Trudeau 2001; and Whipple 2003
Results of the search
The initial searches of CCDANCTR, OVID PsycINFO and PROM bibliographies (to 30 May 2014) yielded 1052, 2535, and 186 references respectively (see PRISMA diagram, Figure 1). The WoS citation search to 5 June 2014 yielded 262 references, and we identified a further 59 references through searching the international trial registers, screening reference lists, and personal communication with trial authors. An updated search (to 18 May 2015) was conducted to validate identified references by re‐searching PsycINFO and CCDANCTR along with The Cochrane Library, which yielded a further 752 references. Following de‐duplication, we screened a total of 4258 references obtained through these searches, of which we excluded 4136 on assessment of the title alone. Of the remaining 122, 99 were excluded on the basis of reading and discussing the abstract (80) or full‐text article (19), including 25 reviews or descriptive articles, 22 where PROMs were not used for outcome monitoring, 19 with ineligible populations (adolescents, severe mental illness, eating disorders, or substance misuse), 14 non‐randomised studies, 13 which included complex quality improvement programmes, three because we were unable to retrieve full references, and three ongoing studies (NCT01796223; NCT02023736; NCT02095457); see PRISMA diagram (Figure 1). Further information is given below on the 19 studies excluded on the basis of reading and discussing the full‐text articles (see Excluded studies).
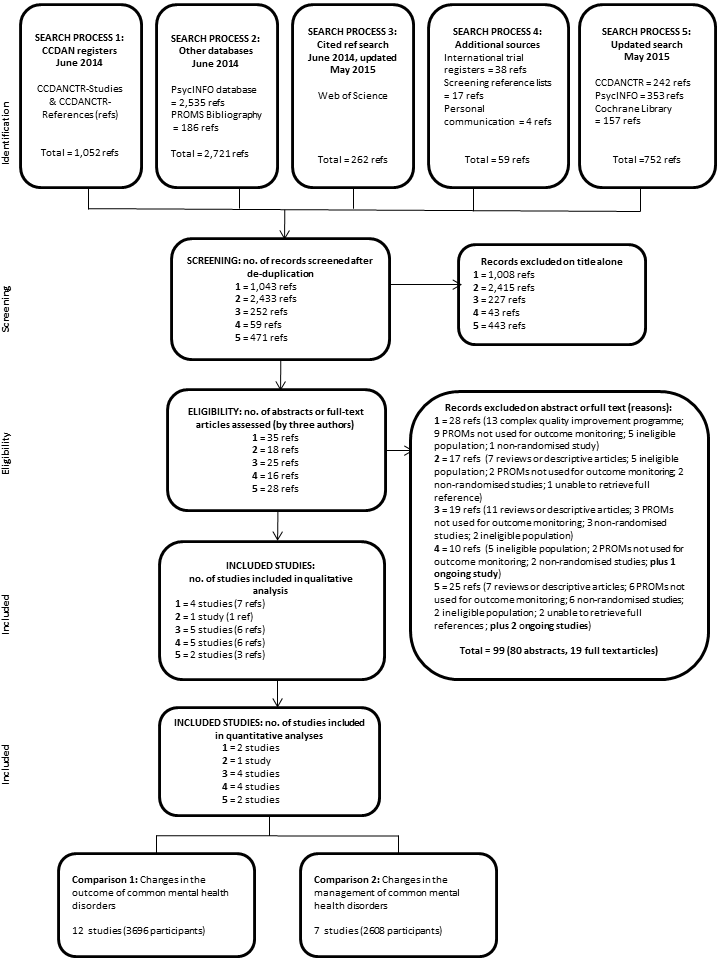
PRISMA flow diagram
In compliance with MECIR conduct standard 37 we ran an update search within 12 months of publication (on 25 May 2016), including the following databases: PsycINFO (which identified 72 references), CCDANCTR (29 references), CENTRAL (37), Web of Science (139), and the ICTRP/ClinicalTrials.gov international trial registries (28): in total 305, and de‐duplicated 281 references. This update search identified two additional completed studies (Gibbons 2015 and Rise 2016) which are awaiting classification, and four additional ongoing studies (Metz 2015; NCT02656641; NTR5466; and NTR5707). These results will be fully incorporated into the review at the next update (as appropriate).
The remaining 23 references described 17 included studies, of which 13 (Amble 2014; De Jong 2012; De Jong 2014; Hansson 2013; Hawkins 2004; Lambert 2001; Murphy 2012; Probst 2013; Reese 2009a; Reese 2009b; Simon 2012; Trudeau 2001; and Whipple 2003) were included in quantitative meta‐analyses as they used comparable outcome measures (either the Outcome Questionnaire (OQ‐45, Lambert 2004) or Outcome Rating System (ORS, Miller 2003), see interventions below), and the remaining four (Berking 2006; Chang 2012; Mathias 1994; Scheidt 2012) were included in the qualitative assessment (see PRISMA flow diagram, Figure 1).
The results of attempts to clarify study details through contacting authors are given in the table below. Contact details were unobtainable for the authors of Mathias 1994. Of those contacted seven authors responded (with regard to De Jong 2012; De Jong 2014; Haderlie 2012; Hansson 2013; Hawkins 2004; Puschner 2009; Reese 2009a; Reese 2009b; and Trudeau 2001;), and the remainder failed to respond (with regard to Chang 2012; Lambert 2001; Probst 2013; Simon 2012; and Whipple 2003).
Included studies
The individual studies are described in detail in the Characteristics of included studies table below.
Design
Thirteen studies were randomised at the individual level and four were cluster randomised (Chang 2012; Mathias 1994; Reese 2009b; Scheidt 2012). Fourteen studies had one intervention arm in which feedback of patient reported outcomes was given, and one control arm in which patients completed the measures but the results were not fed back. De Jong 2014; Hawkins 2004; and Trudeau 2001 included three arms: De Jong 2014 and Hawkins 2004 included two intervention arms, one in which feedback was given to the clinician only and one where feedback was given to both clinician and patient; and Trudeau 2001 included an additional control arm in which patients were not asked to complete the measures at all.
Sample sizes
The number of participants per study ranged from 96 to 1629 with a total of 8787 participants. A substantial proportion of participants were not used in data analysis due to withdrawal or loss to follow‐up, with all but two studies (De Jong 2012; Hansson 2013) utilising only a per protocol analysis. This number totaled 2650 (30.1%).
Setting
The majority of the studies (nine) were carried out in the USA. The remainder were carried out in Germany (three), The Netherlands (two), Sweden (one), Norway (one) and Ireland (one). Fifteen studies were conducted exclusively in outpatient settings, and two, Berking 2006 and Probst 2013, were inpatient studies. One study (Amble 2014) included both inpatients and outpatient clinics. Seven studies were multi‐centre with the remainder confined to one site.
Two studies were based in primary care settings (Chang 2012; Mathias 1994); nine in multidisciplinary mental health care settings (Amble 2014; Berking 2006; De Jong 2012; De Jong 2014; Hansson 2013; Hawkins 2004; Probst 2013; Simon 2012; Trudeau 2001); and six in psychological therapy settings (Lambert 2001; Murphy 2012; Reese 2009a; Reese 2009b; Scheidt 2012; Whipple 2003).
Participants
The 17 included studies comprised 8787 randomised participants (pre‐attrition total), of whom 6137 (69.9%) provided follow‐up data and were included in the study analyses. The age of participants ranged between 18 to 75 years, but in several studies the range was not reported. The median age across the studies was 35.1 years. The proportion of women among participants ranged from 58% to 73%, although there was inconsistency in reporting, with some studies providing the proportion of women among participants randomised, and some the proportion among participants included in the analysis. Reporting of demographic details was quite variable between studies, with marital status and employment being the most commonly recorded demographics. In studies which reported on ethnicity, the majority of participants were white.
Fourteen studies reported specific diagnoses for their participants, of which three used ICD diagnostic criteria (Amble 2014; Berking 2006; Scheidt 2012), and three used DSM criteria (De Jong 2012; De Jong 2014; Mathias 1994). The remaining studies characterised participants on the basis of clinical diagnoses rather than diagnostic criteria. Three studies did not report the specific diagnoses of their participants (Reese 2009a; Reese 2009b; Trudeau 2001), and five did not assign a specific diagnosis of a CMHD to 20% or of their participants, reporting that they had interpersonal or relationship difficulties, other diagnoses including personality or behavioural disorders, or were given administrative codes (Amble 2014; De Jong 2014; Lambert 2001; Murphy 2012; Whipple 2003).
Interventions
Feedback was usually given in the form of scores on the PROMs, together with information on whether this meant the participant had improved or not. Feedback was given only to the clinician in six studies: Chang 2012; Hawkins 2004 (one arm); Mathias 1994; Probst 2013; Scheidt 2012; and Trudeau 2001. Feedback was given explicitly to both the clinician and participant in seven: De Jong 2014 (one arm); Hansson 2013; Hawkins 2004 (one arm); Murphy 2012; Reese 2009a; Reese 2009b; and Simon 2012. In the other seven studies clinicians were permitted or encouraged to share feedback with the participant: Amble 2014; Berking 2006; De Jong 2012; De Jong 2014 (one arm); Lambert 2001; Probst 2013; and Whipple 2003.
Eight different PROMs were used across the studies, the most common being the Outcome Questionnaire‐45 (OQ‐45, Lambert 2004), a compound measure of psychiatric symptoms, individual functioning, interpersonal relations, and performance in social roles, which was used in 10 studies (Amble 2014; De Jong 2012; De Jong 2014; Hansson 2013; Hawkins 2004; Lambert 2001; Probst 2013; Simon 2012; Trudeau 2001; Whipple 2003). As well as the OQ‐45 scores, feedback was colour coded to allow quick appreciation of the extent of change during a busy clinic. In three of these studies (Probst 2013; Simon 2012; Whipple 2003) additional interventions were applied in the 'not on‐track' (NOT) groups, giving clinicians specific instructions on whether or not to change treatment according to the results of the outcome measure, and what further treatments to apply, known as the 'Assessment of Signal Cases' (ASC), and 'Clinical Support Tool' (CST) respectively.
Three studies (Murphy 2012; Reese 2009a; and Reese 2009b) used a shorter measure derived from the OQ‐45, known as the Outcome Rating System (ORS, Miller 2003) which includes the same domains as the OQ‐45.
The duration of the treatment period was variable, being determined by the clinician or patient terminating treatment in most studies, and so the duration of follow‐up was also variable, as the final measure of outcome was usually collected at the last treatment session.
Outcomes
Our primary outcome (mean change in symptom score) was reported by all studies, but of the remaining two primary outcomes health‐related quality of life was assessed by only two of the trials (Mathias 1994; Scheidt 2012), and adverse effects (including suicide and self‐harm) were also assessed by only one (Chang 2012). Changes in the management of the CMHD (pharmacological treatment and referral to secondary care) were reported by two studies (Chang 2012; Mathias 1994), and eight studies reported effects on the number of treatment sessions received by participants (Amble 2014; De Jong 2014; Hawkins 2004; Lambert 2001; Reese 2009a; Reese 2009b; Simon 2012; Whipple 2003).
Timing of outcome assessment
All but two of the studies reported research outcomes only in the short‐term, up to six months after baseline assessment. De Jong 2014 and Scheidt 2012 also reported longer‐term outcomes, after 35 weeks and 12 months respectively.
'On track' and 'not on track' participants
In 10 studies (De Jong 2012; De Jong 2014; Hansson 2013; Hawkins 2004; Lambert 2001; Murphy 2012; Reese 2009a; Reese 2009b; Simon 2012; Whipple 2003) results were reported for subgroups of participants according to whether they were identified early in their treatment as 'on‐track' (OT) or 'not on track' (NOT) for a good clinical response. The NOT group were also sometimes labelled as 'at risk', 'signal cases', or 'signal alert cases'.
Excluded studies
After obtaining and assessing the full text of the report we excluded 19 studies. Six studies were non‐randomised, six did not use the PROM for outcome monitoring or did not report patient outcomes, five included an ineligible population, and two involved the use of a PROM as part of a more complex quality improvement programme. See Characteristics of excluded studies for further details.
Ongoing studies
We identified seven ongoing studies that fitted our inclusion criteria. Three of these studies are comparing feedback to the therapist only with treatment as usual (TAU) (NCT01796223; NCT02023736 and NCT02095457); two are comparing feedback to both therapist and participant with TAU (Metz 2015 and NTR5466); one is comparing feedback to the participant only with TAU (NTR5707), and one has a three‐arm design comparing feedback to the participant only, versus feedback to the participant and therapist, versus TAU (NCT02656641). Outcome is being measured with the OQ‐45 and Beck Depression Inventory (BDI) in NCT02023736; with the CORE‐OM rating scale (Barkham 2006) in NCT02095457 (together with health service utilisation and level of functioning); with the Outcome Rating Scale (ORS) in NCT01796223 and NTR5466; with the PHQ‐9 and GAD‐7 in NCT02656641; and with the Inventory of Depressive Symptomatology (IDS) plus the OQ‐45 in NTR5707. The primary outcome in Metz 2015 is the enablement of shared decision making measured using the Decisional Conflict Scale (DCS), but the OQ‐45 outcome measure is one of the secondary outcomes. Four studies are taking place in multidisciplinary mental health care settings (Metz 2015; NCT01796223; NCT02095457; NTR5707), two in psychological therapy settings (NCT02023736; NCT02656641), and one in both primary care and multidisciplinary mental health care settings (NTR5466). See Characteristics of ongoing studies for further details.
Studies awaiting classification
We identified two completed and published studies, Gibbons 2015 and Rise 2016, which are awaiting classification.
Gibbons 2015 cluster randomised people with depression attending a community mental health centre in Philadelphia, USA, to eight weeks of individual therapy with either a clinician receiving weekly feedback reports, or a clinician not receiving weekly feedback reports, using the BASIS‐24 (24‐Item Behavior and Symptom Identification Scale) as both a PROM and outcome measure. The study reported a medium effect size in favour of the feedback condition for symptom improvement (Effect size (Cohen's d) = 0.50, P value = 0.017), and 36% of feedback participants compared to 13% of participants in the no feedback condition demonstrated clinically significant change across treatment (P value = 0.013).
Rise 2016 cluster randomised outpatients attending a mental health hospital in Norway to feed back to both client and therapist using the PCOMS system PROMs (Outcome Rating Scale (ORS) and Session Rating Scale (SRS)), or to care without feedback, measuring outcomes with the Behaviour and Symptom Identification Scale 32 (BASIS‐32), and Patient Activation Measure (PAM). The study reported that, at 6 and 12 months after starting treatment there were no significant effects on the primary outcomes of mental health symptoms or patient activation, but compared to baseline assessment the PCOMS group had significantly improved their patient activation scores after 12 months.
See Characteristics of studies awaiting classification for further details.
Risk of bias in included studies
We categorised the overall risk of bias for each study, with all studies considered at high risk of bias (a plausible presence of bias that seriously weakens confidence in the results), as one or more domains received a judgement of high risk. In most studies, we judged inadequate blinding and attrition at high risk of bias, see sections below for further details. For details of the risk of bias judgement for each study, see Characteristics of included studies. A graphical representation of the overall risk of bias of included studies is presented in Figure 2 and Figure 3.

Risk of bias summary: review authors' judgements about each risk of bias item for each included study.

Risk of bias graph: review authors' judgements about each risk of bias item presented as percentages across all included studies.
Allocation
This review included studies using either an individual randomisation or cluster randomisation method. The studies that were cluster randomised may be, by method, at risk of selection bias, where concealment of group allocation prior to obtaining consent is not ensured, thereby increasing the likelihood that participants allocated to the intervention group have a propensity to using PROMs. This bias risk is not commented upon by any of those studies using a cluster randomisation, and therefore, it is not possible to exclude a high risk of selection bias.
Sequence generation
Seven of the studies described the means to generate the allocation sequence in sufficient detail to make a favourable assessment of whether comparable groups should be produced (Amble 2014; De Jong 2014; Hansson 2013; Hawkins 2004; Murphy 2012; Simon 2012; Trudeau 2001). After contact with the authors, Reese 2009a; Reese 2009b; and De Jong 2012 were also deemed to have used an adequate means of sequence generation, therefore in total 10 studies were judged at low risk of bias for this domain. A lack of adequate reporting in four studies (Lambert 2001; Probst 2013; Scheidt 2012; Whipple 2003) resulted in a judgement of unclear risk of bias. The remaining three studies were judged at high risk of bias for this domain, as Berking 2006 used coin tossing, and Chang 2012 and Mathias 1994 assigned clinics and call centres, respectively, to feedback and no‐feedback groups without details of how they were randomised.
Allocation concealment
Insufficient details were reported regarding allocation concealment in nine studies, rendering a judgement of unclear risk (Amble 2014; Hawkins 2004; Lambert 2001; Probst 2013; Reese 2009a ; Scheidt 2012; Simon 2012; Trudeau 2001; Whipple 2003). Four studies were considered at low risk of bias (De Jong 2012; De Jong 2014; Hansson 2013; Murphy 2012), while Chang 2012; Mathias 1994; Reese 2009b; Scheidt 2012 were considered to be at high risk, due to their cluster randomised design.
Blinding
Due to the nature of the intervention, it is very difficult to blind the clinicians in studies fitting the inclusion criteria for this review. However, we judged the majority of the studies at high risk of bias as the group allocation was clearly known to the participating clinicians in all but two studies. Chang 2012 was considered to be at low risk as participants in both arms received feedback but the frequency of feedback varied between the two arms, and the participants were unaware of which arm they were in. In the intervention arm feedback was monthly through the six‐month study period and could therefore influence outcome, while in the control arm feedback was not provided until the end of the six‐month period, and so could not affect outcome. Insufficient details were reported in Scheidt 2012, so the risk of bias for this study was judged as unclear.
Similarly, the risk of bias related to blinding of outcome assessors was judged as high for all but three of the 17 studies. In 13 studies the PROM used for feedback was also used for outcome assessment, so the participants themselves were the outcome assessors and they were not blind to whether or not they received the intervention. In the remaining three, the risk of bias was judged to be high in one (Mathias 1994) as the researchers assessing outcome were apparently aware of group allocation; unclear in two, as it was not reported whether allocation was concealed from the outcome assessors (Berking 2006; Scheidt 2012); and low in one (Chang 2012), as, although the PROM used for feedback was also used for outcome assessment, the participants receiving the feedback were unaware of which arm they were in.
Incomplete outcome data
The attrition rate, through loss to follow‐up, was considered to put study results at high risk of bias in all but two of the studies, Berking 2006 and Lambert 2001. This was usually because participants were excluded from the analysis if they did not have at least two outcome measures completed (and sometimes three), as the change in outcome from baseline was measured by the clinician at the last therapy session, and there was no measure of outcome outside the clinical setting by an independent researcher at a predetermined follow‐up point. This may be justified in the sense that only participants who have at least a second outcome measure completed might be considered to have had the 'minimum dose' of feedback necessary to examine its effects, but it means that all of the studies except two were analysed on a per protocol basis rather than according to intention to treat (ITT). Hansson 2013 did report an ITT analysis, and De Jong 2012 used multiple imputation to deal with the problem of missing data at follow‐up.
Lambert 2001 reported no drop‐outs, with all 609 study participants recruited apparently completing the study, but we were unable to confirm that with the author. The risk of incomplete outcome data was low for Berking 2006 as that study of inpatients collected follow‐up data on more than 98% of the participants.
Selective reporting
We looked for published protocols for the included studies, in order to determine whether selective reporting had taken place, but were unable to identify any. Judged from the aims and methods described in the included study reports, the risk of selective reporting bias was judged to be low for nine studies (Amble 2014; Berking 2006; De Jong 2012; De Jong 2014; Hansson 2013; Mathias 1994; Probst 2013; Trudeau 2001; Whipple 2003), while four were judged to have a high risk of reporting bias due to incomplete reporting of primary outcomes (Chang 2012; Lambert 2001; Reese 2009a; Reese 2009b), and for four (Hawkins 2004, Murphy 2012, Scheidt 2012; Simon 2012) it was unclear whether selective reporting had taken place.
Ten studies using the OQ‐45 or ORS PROMs reported results separately for 'on track' (OT) and 'not on track' (NOT) subgroups of participants, but the criteria for defining these subgroups were specified using a priori definitions in the OQ‐45 and ORS systems, and the results were usually reported for both OT and NOT sub‐groups, except for Simon 2012 which did not report data for OT participants.
Other potential sources of bias
We did not identify any other sources of bias.
Effects of interventions
Comparison 1: Treatment informed by feedback of patient reported outcome measures compared with treatment as usual
Primary Outcomes
1.1 Mean improvement in symptom scores
Our primary analysis compared feedback to clinician (with or without feedback to the participant in addition), to no feedback (usual care). Pooling of patient outcome data across studies to provide a summary estimate of effect was possible only for those studies measuring outcome using the OQ‐45 or ORS compound outcome measures as PROMs. There was no evidence of skew, with all values being greater than 2.
a) OQ‐45 PROM
Nine studies (Amble 2014; De Jong 2012; De Jong 2014; Hansson 2013; Hawkins 2004; Lambert 2001; Probst 2013; Trudeau 2001; Whipple 2003) including 3438 participants contributed data to a comparison of studies using the OQ‐45 as both PROM and outcome measure. (Simon 2012 also used the OQ‐45 but could not be included as the study reported results only for 'not on track' patients, see post‐hoc analysis below). This analysis revealed no evidence of a difference between feedback and no‐feedback groups in terms of symptom scores (mean difference (MD) ‐1.14, 95% CI ‐3.15 to 0.86; P = 0.26, I2 = 25%), see Analysis 1.1. The evidence for this comparison was considered low quality. All but one of these studies reported outcomes only in the short‐term, up to 26 weeks post‐baseline. De Jong 2014 reported no significant differences overall between outcomes for short‐term (up to 35 weeks) and long‐term (35 to 78 weeks) treatment.
b) OQ‐45 and ORS PROMs
We combined an additional three studies (Murphy 2012; Reese 2009a; Reese 2009b), with a further 258 participants using the ORS as both a PROM and outcome measure with the studies above in Analysis 1.2 (see summary of findings Table for the main comparison). Again, this analysis revealed no evidence of a difference between feedback and no‐feedback groups in terms of symptom scores (standardised mean difference (SMD) ‐0.07 95% CI‐0.16 to 0.01; P = 0.10, I2 = 30%). The evidence for this comparison was also considered low quality.
c) Other outcome measures
Four studies identified used a variety of measures of global symptoms, depressive symptoms alone, anxiety symptoms alone, or quality of life alone, which we judged too dissimilar to combine, in terms of the domains measured, with the results for the OQ‐45 or ORS, which are compound outcome measures combining symptoms, functioning and relationships, and so these four studies were not included in the meta‐analyses.
Two studies in US primary care populations reported mixed findings.
Chang 2012 measured depressive symptoms using the PHQ‐9 depression questionnaire as both PROM and outcome measure, and reported a significantly greater odds of response in terms of changes in scores on the PHQ‐9 significant difference between feedback (n = 364) and no feedback (n = 278) groups (odds ratio (OR) 2.02, 95% CI 1.36 to 3.02).
Mathias 1994 developed a composite PROM, the Mental Health Patient Profile, constructed from the symptom checklist SCL‐90, diagnostic interview schedule DIS, and quality of life short form SF‐36 scales. Outcome was measured in terms of overall symptom severity using the Global Severity Index (GSI), and anxiety symptoms using the Highest Anxiety Subscale Score (HASS). They reported no significant differences between feedback (n = 367) and no feedback (n = 216) groups in either GSI or HASS. At completion of the study, the mean GSI for the feedback group was 59.90 and for no feedback 60.89, P = 0.89. Similarly, no significant difference between feedback and no‐feedback groups was seen in mean HASS scores (feedback group 64.72, no feedback 68.23, P = 0.74).
The quality of evidence for these outcomes was graded as moderate.
Two German studies used compound questionnaires as both PROMs and outcome measures.
Berking 2006 used a compound questionnaire for assessing success and course of psychotherapeutic treatment (FEV) to monitor progress in inpatients in multidisciplinary mental health care. The FEV included an emotionality inventory (EMI‐B); a brief symptom inventory (BSI); an inventory of interpersonal problems (IIP‐D); and a measure of cognitive changes (INK), and gave a compound score. FEV scores were compared between feedback (n = 40) and no‐feedback groups (n = 39) at the end of their inpatient stay, and a more favourable effect was reported in the feedback group: a change from a mean pre‐study score of 2.90 (SD 0.62) to 2.25 (0.71), compared with 2.91 (0.69) to 2.54 (0.77) in the no feedback group.
Scheidt 2012 also used a compound comprehensive inventory of psychometric measurement instruments to monitor psychotherapy outpatients. Based on the scores, decision rules ('reorientation of the expert system') were developed and optimised to guide decisions about indications for, and prolongation of, psychotherapy based on the feedback received (‘TK system’). The compound measure also assessed several outcomes: a brief symptom inventory (BSI), inventory of interpersonal problems (IIP‐D), Beck Depression Inventory (BDI); and a questionnaire on body‐related anxiety and cognitions (AKV). There was no difference seen in the BSI between the feedback (302) and no‐feedback groups (160) at 12 months post treatment (MD 1.00, 95% CI ‐2.22 to 4.22; P = 0.54). There was a slightly better outcome seen in the IIP‐D score in the feedback group (n = 305, control n = 158) but this was not significant (MD 2.30, 95% ‐0.37 to 4.97; P = 0.09). However, the feedback group (n = 205) scored significantly better on the BDI questionnaire than the no feedback group (n = 124) (MD 4.60, 95% CI 0.79 to 8.41; P = 0.02). On assessment with the AKV, there was no difference seen between groups (feedback n = 71, control n = 24) (MD ‐1.50, 95% C.I. ‐7.31 to 4.31; P = 0.61).
The quality of evidence for these outcomes was graded as moderate to low.
1.2 Health‐related quality of life
We did not pool data for this outcome as it was reported by only two studies.
Mathias 1994 assessed quality of life using the 36‐item Short Form (SF‐36) scale. They reported no significant difference between feedback (n = 367) and no feedback (n = 216) groups in any of the nine sub scales of the SF‐36. Mean mental sub scale scores were 66.0 for feedback and 64.8 for no‐feedback groups (P = 0.31).
Scheidt 2012 assessed quality of life using the 12‐item Short Form (SF‐12) scale, reporting results for mental and physical sub scales. There were no significant differences seen between feedback (n = 376) and no feedback (n = 211) groups at the end of treatment, for both physical (MD ‐0.90, 95% CI ‐3.11 to 1.31; P = 0.55) and mental sub scales (MD 1.20, 95% CI ‐0.51 to 2.91; P = 0.55).
The quality of evidence for these comparisons was graded as moderate to low.
1.3 Adverse events
Only one study reported any findings in relation to adverse events: in Chang 2012, 273 PHQ‐9 questionnaires elicited thoughts of suicide or self‐harm and no immediate suicide risk was discerned. However, information on which arms these findings were in was not provided.
Adverse events from prescribed medication were not assessed in any of the included studies.
Secondary outcomes
1.4 Changes in management of CMHDs
a) Changes in prescribed drug treatment
Only two studies reported differences in changes of prescribed drug treatment. Chang 2012 showed that, at six months, 200/352 in the feedback and 115/252 in the no feedback group had no change in pharmacological treatment. Percentages without a change in antidepressant therapy did not differ significantly between study arms (OR 1.21 95% CI 0.78 to 1.88; P = 0.06). Mathias 1994 also reported no significant difference between feedback and no‐feedback groups in changes in prescriptions for psychotropic medications (OR 1.09, 95% CI 0.94 to 1.85).
b) Referrals
Only Mathias 1994 assessed levels of referral to 'mental health specialists', without distinguishing between psychiatry and psychology referrals, and reported that referrals were significantly more likely in the feedback group (OR 1.73, 95% CI 1.11 to 2.70).
c) Number of treatment sessions received
An addition to the planned comparisons of changes in management of CMHDs was made post‐hoc (see Differences between protocol and review section), namely an analysis of differences in the mean number of treatment sessions received between feedback and no‐feedback groups. Data from seven studies that reported numbers of treatment session (Amble 2014; De Jong 2014; Hawkins 2004; Lambert 2001; Reese 2009a; Reese 2009b; Whipple 2003) were pooled, including 2608 participants, in an analysis which showed no evidence of a difference in the mean number of treatment sessions between feedback and no‐feedback groups (MD ‐0.02 sessions, 95% CI ‐0.42 to 0.39; P = 0.93, I2 = 0%), see Analysis 1.3 and summary of findings Table for the main comparison.The quality of evidence for this outcome was graded as low.
Probst 2013 also reported no significant differences between feedback and no‐feedback groups in the number of weeks (rather than sessions) of treatment received.
1.5 Social functioning
Only one study reported differences in social functioning. Hansson 2013 found no differences between feedback and no‐feedback groups in mean scores on the sub scale of the OQ‐45 relating to social functioning (feedback group (n = 136) 13.9, no feedback group (n = 126) 14.9, P = 0.10).
1.6 Costs
No studies reported any cost data.
Subgroup analyses
2. Whether the setting of the study influenced the success of the strategy
We could only carry out subgroup comparisons for the primary outcome of mean improvement in symptom scores, due to the lack of data on health‐related quality of life and adverse effects.
2.1 Setting 1: Primary care
2.1.1 Mean improvement in symptom scores
Neither study from a primary care setting was included in the meta‐analyses above, as they did not use the OQ‐45 or ORS, and so could not be considered within this subgroup analysis.
2.2 Setting 2: Multi‐disciplinary mental health care settings
2.2.1 Mean improvement in symptom scores
Seven studies in multidisciplinary mental health care (Amble 2014; De Jong 2012; De Jong 2014; Hansson 2013; Hawkins 2004; Probst 2013; Trudeau 2001) comprising 1848 participants assessed the effect of the OQ‐45 questionnaire as a PROM feedback tool. These data were pooled in a meta analysis, see Analysis 2.1.1 This showed no evidence of a difference between feedback and no‐feedback groups (SMD ‐0.05, 95% CI ‐0.18 to 0.07; P = 0.40, I2 = 37%). The quality of evidence for this comparison was also graded as low.
2.3 Setting 3: Psychological therapies
2.3.1 Mean improvement in symptom scores
Five studies undertaken in psychological therapy service settings (Lambert 2001; Murphy 2012; Reese 2009a; Reese 2009b; Whipple 2003) comprising 1848 participants were pooled in a meta‐analysis assessing the effect of the OQ‐45 or ORS as a feedback tool, see Analysis 2.1.2. This again showed no evidence of a difference between feedback and no‐feedback groups in terms of symptom scores (SMD ‐0.10, 95% CI ‐0.23 to 0.03; P = 0.14, I2 = 29%). The quality of evidence for this comparison was also graded as low.
There was no significant difference between the results obtained for the subgroup of studies carried out in multi‐disciplinary mental health care settings and those carried out in psychological therapy settings (test for subgroup differences: Chi² = 0.23, df = 1 (P = 0.63), I² = 0%).
3: Whether participants who had a formal diagnosis made using ICD or DSM criteria were likely to do better than those where no formal diagnosis was made
3.1 Mean improvement in symptom scores
In three studies within the meta‐analysis (Amble 2014; De Jong 2012; De Jong 2014), including 1144 participants, the participants were given formal diagnoses. There was no evidence of a difference between feedback and no‐feedback groups (SMD ‐0.01, 95% CI ‐0.23 to 0.21), see Analysis 3.1.1 and no evidence of benefit was observed in the subgroup analysis limited to the nine studies in which no formal diagnoses were given (SMD ‐0.08, 95% CI ‐0.15 to 0.00; P = 0.06, I2 = 0%), see Analysis 3.1.2. There was no significant difference between the subgroup of studies where a formal diagnosis was given and those without a formal diagnosis (test for subgroup differences: Chi² = 0.28, df = 1 (P = 0.60), I² = 0%). The quality of evidence for these outcomes was graded as low.
4: Studies of participants aged 18 to 65 years versus those with participants aged over 65 years
This planned subgroup comparison was not possible as no studies distinguished subgroups of participants in the two age categories.
5: Studies where feedback was given only to clinicians versus studies where feedback was given to both clinicians and participants
5.1: Mean improvements in symptom scores
Feedback was given only to the clinician in six studies: Chang 2012; Hawkins 2004 (one arm); Mathias 1994; Probst 2013; Scheidt 2012; and Trudeau 2001. Feedback was given explicitly to both the clinician and patient in seven: De Jong 2014 (one arm); Hansson 2013; Hawkins 2004 (one arm); Murphy 2012; Reese 2009a; Reese 2009b; and Simon 2012. In the other seven studies clinicians were permitted or encouraged to share feedback with the patient: Amble 2014; Berking 2006; De Jong 2012; De Jong 2014 (one arm); Lambert 2001; Probst 2013; and Whipple 2003. Subgroup analyses showed no evidence of differences in outcomes between these three groups as the confidence intervals overlapped for all analyses (a formal statistical test for difference between subgroups was not carried out as some studies contributed data to more than one subgroup, potentially violating the assumption of independence). See Analysis 4.1.
6: Studies where feedback of PROM results was given only to the participants and not to the clinicians
This planned subgroup analysis was not possible as no studies were identified in which feedback was given only to participants and not to clinicians.
7: Studies where feedback to the clinician included treatment instructions or an algorithm in addition to a score on a PROM
7.1 Mean improvement in symptom scores
Two studies in the meta‐analysis, including 1184 participants, included treatment instructions in the form of a clinical support tool (CST) for those found to be not on track (NOT): Probst 2013 and Whipple 2003. (Simon 2012 also included a CST but provided data only for the NOT participants). A subgroup analysis comparing these two with the remainder showed no significant differences in either subgroup (test for subgroup differences: Chi² = 0.64, df = 1 (P = 0.42), I² = 0%). For those studies with a CST: SMD ‐0.03 (95% CI ‐0.14 to 0.09; P = 0.66, I2 = 0%), compared to: SMD ‐0.09 (95% CI ‐0.20 to 0.02; P = 0.11, I2 = 38%) for those studies without a CST, see Analysis 5.1.1 and 5.1.2.
Post‐hoc sub‐group analysis of studies involving Michael Lambert, the originator of the OQ‐45 PROM and feedback system, versus studies not involving him
8.1 Mean improvement in symptom scores
Six studies included in this review involved Michael Lambert as either first author or co‐author. There was no significant difference in the overall findings in terms of outcomes observed between a subgroup of five studies which included him as an author (see Analysis 6.1.1) and four which did not (Analysis 6.1.2) (test for subgroup differences Chi² = 0.18, df = 1 (P = 0.67), I² = 0%).
Post‐hoc analyses of subgroups of 'on track' and 'not on track' participants
1. Improvement in symptom scores among 'not‐on‐track' participants
Ten studies including 923 participants identified participants who were considered 'not on track' (NOT), 'at risk', or 'signal alert cases' early on during their treatment, and provided separate data for these participants, see Analysis 7.1. Symptom scores were slightly lower in the feedback group compared to the no feedback group in this subgroup (SMD = ‐0.22, 95% CI ‐0.35 to ‐0.09; P = 0.001, I2 = 0%). The quality of evidence for this comparison was graded as low.
2. Number of treatment sessions received: 'on track' and 'not on track' participants
Five studies reported differences in the number of treatment sessions received between feedback and no‐feedback groups for NOT participants. Data from De Jong 2014; Hawkins 2004; Lambert 2001; Reese 2009b and Whipple 2003 were pooled in a meta‐analysis which demonstrated no evidence of a difference in the mean number of therapy sessions received (see Analysis 7.2). In addition, Probst 2013 reported that for the NOT subgroup of participants, there was no significant difference between feedback and no‐feedback groups in the number of weeks (rather than sessions) of treatment received: 6.22 (SD 3.29) compared to 5.49 (3.17), P = 0.46. Four studies (De Jong 2014; Lambert 2001; Reese 2009b; Whipple 2003) reported differences in the amount of therapy received between feedback and no‐feedback groups for the subgroup of 'on track' (OT) participants only. The mean number of treatment sessions was slightly fewer in the feedback group: (MD ‐0.69, 95% CI ‐1.10 to ‐0.29; P = 0.0007, I2 = 0%). However, a formal test for subgroup differences revealed no significant difference between findings for OT and NOT participants (chi2 = 0.99, df = 1 (P = 0.32), I2 = 0%, see Analysis 7.2). The quality of evidence for this comparison was also graded as low.
Sensitivity analyses
The following planned sensitivity analyses were not possible:
-
Whether the mode of administration (self‐complete versus clinician‐rated) influenced the success of the strategy, because the main analysis did not include any studies using clinician‐rated PROMs.
-
Whether cluster randomised studies produced a different result from non‐clustered studies, because the main analysis included only one cluster randomised study, Reese 2009b.
-
Within cluster RCTs, whether adjustment for unit of analysis error influenced the results, again because the main analysis included only one cluster randomised study, and Reese 2009b did report that the results were adjusted for clustering.
-
Whether the inclusion of quasi‐randomised cluster trials significantly affected the results, because the main analysis did not include any quasi‐randomised cluster trials.
The only sensitivity analysis which could be carried out was:
5. Whether losing the data from three‐arm trials (that compared PROMs fed back to the clinician only, versus PROMs fed back to both the clinician and participant, versus treatment as usual), made a significant difference to the results of the subgroup analysis, by excluding such trials from the subgroup analysis.
Two studies (De Jong 2014; Hawkins 2004) included the three arms. No difference was seen in the overall result when these studies were omitted altogether from the meta‐analysis: (SMD ‐0.02, 95% CI ‐0.011 to 0.07; P = 0.68, I2 = 39%), although the direction of the treatment effect was slightly more in favour of the feedback group. Excluding the two studies which included three arms did not make a difference to the subgroup analysis which still showed no significant difference between the subgroups (test for subgroup differences: Chi² = 1.92, df = 2; P = 0.38, I² = 0%).
Post‐hoc sensitivity analysis: unreported or incomplete diagnoses of study populations
Three studies included in the meta‐analyses did not report the specific diagnoses of their participants (Trudeau 2001; Reese 2009a; Reese 2009b), and five did not assign a specific diagnosis of a CMHD to 20% or more of their participants (Lambert 2001; Whipple 2003; Murphy 2012; De Jong 2014; Amble 2014). A sensitivity analysis of the meta‐analysis of studies using the OQ‐45 (Analysis 1.1) omitting Lambert 2001; Trudeau 2001; Whipple 2003; De Jong 2014 and Amble 2014 showed no evidence of a difference in the overall result (MD ‐0.94, 95% CI ‐3.67 to 1.78). Similarly, a sensitivity analysis of the meta‐analysis of studies using either the OQ‐45 or ORS (Analysis 1.2), omitting all eight studies, showed no evidence of a difference (SMD ‐0.03, 95% CI ‐0.12 to 0.06).
Exploration of heterogeneity
We found I2 values between 30% and 69%, indicating moderate to significant heterogeneity, in our main meta‐analysis of the difference in outcome feeding back OQ‐45 or ORS scores versus no feedback, and in seven of our subgroup analyses. Investigating the sources of heterogeneity in these comparisons, we found that they nearly all included Amble 2014 which reported distinctly positive findings. The authors reported that only 25% of the therapists employed at their clinics agreed to participate, which is a small proportion compared to the other studies included, which usually involved all or most of the therapists working in a service. Also, three quarters of the participants included were seen in the clinic where the project leader and main coordinator worked, underlining "the importance of having a dedicated local advocate monitoring and following up the procedures for using a feedback system" (Amble 2014, p.6). It seems likely therefore that the therapists seeing clients in that study were self‐selected for their enthusiasm for routine monitoring.
Reporting Bias
Funnel plots conducted for publication bias in relation to the meta‐analyses of outcomes measured using the OQ‐45 only (Analysis 1.1) and OQ‐45 plus ORS (Analysis 1.2), are shown in Figure 4 and Figure 5 respectively. The Egger test (Egger 1997) indicated that there was no evidence of publication bias in Analysis 1.1 (P = 0.499) or Analysis 1.2 (P = 0.512).
Funnel plot of comparison: 1 Difference in outcome feeding back OQ‐45 or ORS scores versus no feedback, outcome: 1.1 Mean improvement in symptom scores: OQ‐45 PROMS.
Funnel plot of comparison: 1 Difference in outcome feeding back OQ‐45 or ORS scores versus no feedback, outcome: 1.2 Mean improvement in symptom scores: OQ‐45 or ORS PROMs.
Discussion
Summary of main results
In terms of improvements in the outcome of CMHDs, we found no evidence of a difference between feedback and no‐feedback groups in our meta‐analysis of 12 studies using the OQ‐45 or ORS PROMs. We also found no evidence of an effect on the management of CMHDs in terms of the number of treatment sessions participants received, in an analysis combining the results of seven studies using the OQ‐45 or ORS (see summary of findings Table for the main comparison). However, because the evidence we identified is of low quality, we are uncertain about this result, and further research is very likely to have an important impact on our confidence in the estimate of effect and is likely to change the estimate.
The majority of the eligible studies we identified were conducted in multidisciplinary mental health care settings (nine) or psychological therapy settings (six). We identified only two eligible studies conducted in primary care settings, and we were unable to include them in our meta‐analyses as they measured research outcomes with single symptom, global improvement, or quality‐of‐life domains, which were different to the OQ‐45 and ORS which are compound outcome measures combining symptoms, social functioning and interpersonal relationships. A qualitative assessment of the two primary care studies showed conflicting findings: Chang 2012 found a significant difference in outcome but Mathias 1994 found none, while Mathias 1994 found significant effects on the management of CMHDs but Chang 2012 found none (see summary of findings Table for the main comparison).
We did find a difference in outcomes favouring feedback, but with a small effect size (a standardised mean difference of ‐0.22), in a post‐hoc meta‐analysis including only the subgroup of 'not on track' (NOT) participants monitored in 10 studies using the OQ‐45 or ORS PROMs. We also found a small reduction in the number of treatment sessions received for the 'on‐track' (OT) subgroup in another post‐hoc analysis of four studies using the OQ‐45 or ORS (a mean difference of ‐0.69 sessions), but a formal test of subgroup differences revealed no evidence of a difference in the number of treatment sessions received between OT and NOT subgroups of patients.
Overall completeness and applicability of evidence
Most of the outcomes that we anticipated might be affected were not addressed by the majority of studies. Health‐related quality of life, social functioning, and adverse events were each considered only in one or two studies, while the costs of intervention were not considered in any (see summary of findings Table for the main comparison). Similarly, most studies did not report changes in the management of CMHDs in terms of drug treatment or referrals to other specialities, and only a minority reported effects on the number of sessions of treatment received by participants. We were therefore unable to answer all the questions we set out to address.
The meta‐analyses we conducted included studies in multidisciplinary mental health care and psychological therapy settings only, with no inclusion of studies in primary care, as both primary care studies we identified used outcome measures with different domains which were not directly comparable to the OQ‐45 or ORS.The evidence we have been able to analyse is therefore largely limited to the effects of compound PROMs measuring psychological symptoms, functioning, and relationships in one instrument rather than single domain instruments, and in multidisciplinary mental health care and psychological therapy settings, rather than in primary care. This is unfortunate given that the large majority of people with CMHDs are treated in primary care, if they receive treatment at all (McManus 2009), at least in countries with well developed systems of primary care. This contrasts with the relatively large number of studies which have been conducted using patient reported measures for screening and initial identification of CMHDs in primary care (Gilbody 2008). Our findings are therefore consistent with those of Shaw 2013, who concluded that there is a lack of evidence to support recommendations for routine monitoring of people with CMHDs using PROMs in primary care.
It is perhaps not surprising that most of the studies have been conducted in psychological therapy or multidisciplinary mental health care settings, given that people attending these services have a relatively more homogeneous set of presenting problems, and the service staff have a relatively homogeneous professional background, because the services are limited to mental health problems. Introducing routine outcome monitoring of CMHDs in primary care is more challenging, given that primary care deals with the whole range of initially undifferentiated physical, mental and social problems, and so only a minority of people seen in that setting will have CMHDs. In services dedicated to psychological therapies and mental health it is likely to be easier to train staff to routinely administer PROMs to all attending patients, and develop efficient administrative systems and information technology to support monitoring, whereas in primary care staff firstly have to decide which patients have CMHDs and then whether to administer PROMs when relevant, and developing systems to deal with routine outcome monitoring may be regarded as less worthwhile when the patients to be monitored are in a minority. It is questionable therefore whether any benefits identified from routine outcome monitoring in psychological therapy or mental health care settings can be extrapolated to primary care, as patient engagement, the development of routine systems for administering PROMs, and the technical resources and healthcare professional training required to interpret them, may all be more challenging in the primary care setting where only a proportion of patients present with CMHDs.
Quality of the evidence
We rated the quality of the evidence, summarised in summary of findings Table for the main comparison, as low or moderate. The main reasons for the low quality rating were limitations in study design, with regard to lack of blinding of clinicians, participants and outcome assessors; attrition; and indirectness of the evidence. All of the included studies were judged to be at high risk of bias and so we exercise caution in our interpretation of the findings based on the low to moderate quality observed. Specific considerations are discussed below.
Limitations in study design and implementation
The quality of evidence in almost all studies was downgraded due to issues of blinding. Chang 2012 was the only study that executed a study design that blinded clinicians and participants to the differences in frequency and timing of feedback between intervention and control arms, and this study was not included in any of the meta‐analysis. Due to the absence of such blinding, most studies were considered high risk with respect to this domain (see Figure 2). Additionally, all but three studies were judged at high risk of bias when considering the blinding of outcome assessors, as in most studies the PROMs used for feedback were also used for outcome assessment. Shimokawa 2010 called this the "monomethod", and it increases the risk of observer rating bias, as the therapist using the PROM as a clinical intervention can potentially influence the research outcome when it is based on the same PROM. Only one study, Chang 2012 was judged to be at low risk of bias for outcome assessment as, although the PROM used for feedback was also used for outcome assessment, the study was cluster randomised and participants receiving the feedback were not aware of the two conditions operating.
Problems contacting several of the study authors meant no clarification could be obtained regarding randomisation and blinding, so we could not upgrade the evidence for these studies.
A significant proportion of the participants were lost to follow‐up, around 30% altogether, and in all but two studies a per protocol analysis was carried out. Only two studies, Berking 2006 and Lambert 2001, were graded at low risk of bias as there was no attrition at all reported in these two studies. Per protocol analyses were usually conducted because the PROM was used not only as the clinical intervention but also to measure the research outcome, and there was no independent follow‐up by researchers after participants had completed therapy.
Consistency of effect
The effect of treatment across the studies was fairly consistent, with minimal heterogeneity observed in the main analyses. The effect of feeding back PROMs was modest and present in most studies and any inconsistency was minimal within a small and overall insignificant treatment effect. Heterogeneity was more apparent in those subgroup analyses which included Amble 2014, which was unusual in demonstrating an apparently high level of clinician commitment to using PROMs.
Imprecision of the results
The evidence was not downgraded for imprecision in summary of findings Table for the main comparison as the sample sizes exceeded the optimal information size with resultant narrow confidence intervals. However, due to the limitations of study design and implementation, we have been cautious in interpreting the precision of results overall. Precision was reduced in the analysis of subgroups of OT and NOT participants although this is to be expected due to the reduced sample size for each subgroup.
Indirectness of the results
The review included studies involving several groups of participants: primary care patients, clients attending for psychological therapies, and clients under the care of multidisciplinary healthcare teams, both as inpatients and outpatients. A broad spectrum of participants was therefore included, but only two studies were based in primary care, and pooling of data was not possible for these studies as they used PROMs which did not measure the same domains as those used in psychological therapy and multidisciplinary mental health care settings. The OQ‐45 compound outcome measure was used in 10 of the included studies and the ORS, which was derived from the OQ‐45, was used in another three. The preponderance of studies using these scoring systems means we have minimal evidence on which to base judgements of the use of other, quicker to administer, single domain PROMs such as the PHQ‐9 which is widely used in the USA (HRSA 2005) and UK (IAPT 2011).
All included studies provided outcome data on the change in symptom scores, but it was disappointing that most of the other outcomes pre‐specified for this review were not considered by the trials identified. Numbers of treatment sessions were reported in half of the studies, but other important indicators of changes in management such as drug prescription changes or referral for further treatment were reported in only two, and consideration of adverse events, social functioning, and estimates of costs, were almost completely lacking. Consequently, the quality of evidence has to be rated as low in relation to the indirectness of the results.
Publication bias
The funnel plots (Figure 4; Figure 5) and Egger tests for publication bias suggest publication bias was not an issue in this review. However it must be noted that there were only just sufficient numbers of studies to be considered for a formal publication bias assessment.
Potential biases in the review process
We carried out a comprehensive search for eligible studies, using multiple electronic databases, followed up with searching of reference lists, citation searches, and contact with study authors who identified further studies in some cases, in particular Kim de Jong who was therefore invited to be a co‐author. We were also able to include two German studies, as we recruited Anna Brütt, who is German, as a co‐author to help with data extraction. However, all but two of the studies identified were published after the year 2000, apart from Brody 1990 and Mathias 1994, which gives cause for concern that we might have missed studies published in the period 1994‐2000. Although thorough and comprehensive searches were performed to identify all potential studies for inclusion, the searches were initially very inefficient due to the rather non‐specific terms 'feedback' and 'monitor*' capturing many papers which were not actually about using feedback as an intervention to monitor patients' progress. This became more apparent on running the citation searches which yielded further study reports which were not originally identified. We were also unable to contact study authors in a number of cases, in particular Michael Lambert who was a co‐author on six studies, who might have been able to identify further studies for us. It is possible therefore that we failed to identify relevant studies.
A number of studies did not characterise a significant proportion of their participants in terms of underlying diagnoses, as indicated in the Characteristics of included studies section, and in three studies no diagnoses were reported at all (although the lead authors confirmed the large majority participants had CMHDs). We intended to include samples without a formal diagnosis, as they are common especially in the psychological therapy setting, but we also made post‐hoc decisions to include studies where 20% or more of participants were reported to have relationship or interpersonal problems, or received administrative codes only, as long as the majority of those diagnosed were given a diagnosis of a CMHD, and as long as fewer than 10% were diagnosed with a severe mental illness, substance misuse, learning difficulty, dementia, or eating disorder. The lack of specific diagnoses for many participants is a significant limitation of the available literature, and we recommended that future studies characterise the diagnoses of all their participants systematically.
Agreements and disagreements with other studies or reviews
Our results are less positive in terms of favouring the routine use of PROMs than those reported in an earlier meta‐analysis of three studies in psychological therapy settings using the OQ‐45 (Lambert 2003), which reported a small but significant overall positive effect on outcome (an effect size of 0.09), and a larger significant positive effect in the subgroup of NOT participants (effect size of 0.39, compared to 0.22 in our analysis). However, Lambert 2003 included a study (Lambert 2002) which we judged non‐randomised as it used 'historical controls' (i.e. it used archived data from clients previously treated in the clinic as control data, rather than randomising subjects to a control arm) and was therefore excluded from our analysis, as non‐randomised studies confer a greater risk of bias.
Our findings also differ from those of Knaup 2009, who reported an overall significant positive effect of routine monitoring on outcomes (effect size 0.10) from a meta‐analysis of 12 studies in multidisciplinary mental health care and psychological therapy settings. Knaup 2009 also reported a greater effect size (0.30) for studies including feedback of PROM results to patients than for those where feedback was given only to the clinician (0.09), which we did not find. However, Knaup 2009 included only five of the studies included in our review (Berking 2006; Hawkins 2004; Lambert 2001; Trudeau 2001; Whipple 2003), and a further seven studies which were excluded from this study, including two non‐randomised studies (Lambert 2002; Slade 2008), and five which were conducted with people with eating disorders or severe mental illness. Again, non‐randomised studies confer a greater risk of bias, and studies including people with severe mental illness might be more positive, as patients' symptoms are more severe, so the potential for improvement is greater than among people with CMHDs, where a possible 'floor effect' might limit the potential to show a benefit from monitoring with PROMs.
More positive findings than ours were also found by Shimokawa 2010 in an update of the Lambert 2003 meta‐analysis, which added three more studies using the OQ‐45, and reported an overall effect size of 0.12 in favour of outcome monitoring. They also reported a larger effect size among the NOT subgroup of participants, of 0.28, in an intention to treat (ITT) analysis utilising last observations carried forward (LOCF), and an even larger effect size among NOT participants in a per protocol analysis, of 0.53. However, three of the six studies included in Shimokawa 2010 were not randomised trials (Harmon 2007; Lambert 2002; Slade 2008), as they used 'historical controls' and so again were excluded from our analyses due to the increased risk of bias. We were unable to carry out any corresponding ITT analyses using LOCF data, as we could not obtain further data from study authors for several of the studies we included.
Another possible reason for differences between our review and the earlier reviews is that ours included later studies which did not involve the originators of the OQ‐45 system, whose authors might therefore have had less allegiance to the system, and less adherence to its founding principles, thereby diluting its effects. However, we found no evidence of differences between intervention and control groups in a post‐hoc subgroup analysis of the results of five studies authored or co‐authored by Michael Lambert, the originator of the OQ‐45 system, which was similar to the findings among four studies which did not involve him.
Our findings are consistent with those of a more recent systematic review of studies limited to the use of the OQ‐45 or ORS in psychological therapy settings (Davidson 2014), which also concluded that the benefit of feedback monitoring appeared to be limited to NOT participants, although Davidson 2014 did not conduct a meta‐analysis. Their review also included the three studies with historical controls (Harmon 2007; Lambert 2002; Slade 2008), as well as a study of people with substance misuse (Crits‐Christoph 2012), and one of people with eating disorders (Simon 2013), all of which were ineligible for inclusion in this review. Davidson 2014 pointed out, as we have, that many studies were of low quality due to methodological issues.
Our findings relating to the primary care setting are also consistent with those of Shaw 2013, the main finding being a distinct lack of research on the monitoring of CMHDs with PROMs in primary care when compared with multidisciplinary mental health care and psychological therapy settings. We were able to identify only two trials (one of which, Chang 2012, was considered by Shaw 2013), which reported conflicting findings in terms of impacts on the outcome and management of CMHDs. Our findings in primary care settings are also consistent with Gilbody 2002 who failed to identify a positive impact of patient‐centred outcome instruments assessing patient needs or quality of life in non‐psychiatric settings.
Our findings are less positive than those of Carlier 2012 and Poston 2010 which both included studies of the use of PROMs as screening or diagnostic tools together with studies of their use as follow‐up monitoring measures, and so were not directly comparable. They are more consistent with Boyce 2013, Marshall 2006 and Valdera 2008, who all found the evidence of benefit from monitoring with PROMs to be weak, although again they are not directly comparable to our review, as they included studies of the use of PROMs in the management of physical disorders as well as studies in mental health care. Carlier 2012 recommended further research was needed in mental health care, a recommendation we make below. Boyce 2013 and Valdera 2008 pointed out that most of the studies they identified suffered from methodological limitations, as we have found in this review, and that there was significant heterogeneity.
Heterogeneity in this review was apparently related to clinician commitment to using PROMs, as the outstandingly positive finding was found by Amble 2014 in which therapists self‐selected as participants for their interest in using the OQ‐45 PROM. De Jong 2012 looked at therapist variables that moderated feedback effects, and found that improved outcomes in NOT patients were associated with greater commitment to using feedback, perceived validity of feedback, and self‐efficacy among participating therapists.
Other factors which have been suggested by Krageloh 2015 as important in explaining differences in the findings between trials include: having a formalised structure which maximises the likelihood that feedback is discussed with clients; the use of computerised support tools; greater frequency of feedback; and whether PROMs are discussed with clinicians, although Krageloh 2015 did not conduct any meta‐analyses to support those suggestions. We found no difference in outcome between our subgroup analysis of two studies where a clinical support tool (CST) was used to guide responses to scores on the OQ‐45, compared to the remaining studies without CSTs. It has also been suggested that feedback given to both clinicians and patients is more effective than feedback to clinicians alone (De Jong 2012; Hawkins 2004; Knaup 2009), but we did not find that to be the case in our analyses of three subgroups: feedback limited to the clinician; feedback which could be shared with the patient; and feedback routinely provided to the patient as well as the clinician.
Our findings may be contrasted with those of a Cochrane review of collaborative care for depression and anxiety disorders, which found that, compared to usual care, it was associated with significant improvement in symptoms, quality of life, and patient satisfaction (Archer 2012). Collaborative care usually includes feeding back the results of PROMs at initial assessment and follow‐up to inform treatment, but collaborative care includes a number of other active components such as medication management and increased liaison between healthcare professionals, and the process of measuring and feeding back patient outcomes was actually the control condition in some trials of collaborative care interventions (Archer 2012).
Risk of bias summary: review authors' judgements about each risk of bias item for each included study.
Risk of bias graph: review authors' judgements about each risk of bias item presented as percentages across all included studies.
Funnel plot of comparison: 1 Difference in outcome feeding back OQ‐45 or ORS scores versus no feedback, outcome: 1.1 Mean improvement in symptom scores: OQ‐45 PROMS.
Funnel plot of comparison: 1 Difference in outcome feeding back OQ‐45 or ORS scores versus no feedback, outcome: 1.2 Mean improvement in symptom scores: OQ‐45 or ORS PROMs.

Comparison 1 Difference in outcome feeding back OQ‐45 or ORS scores versus no feedback, Outcome 1 Mean improvement in symptom scores: OQ‐45 PROMS.
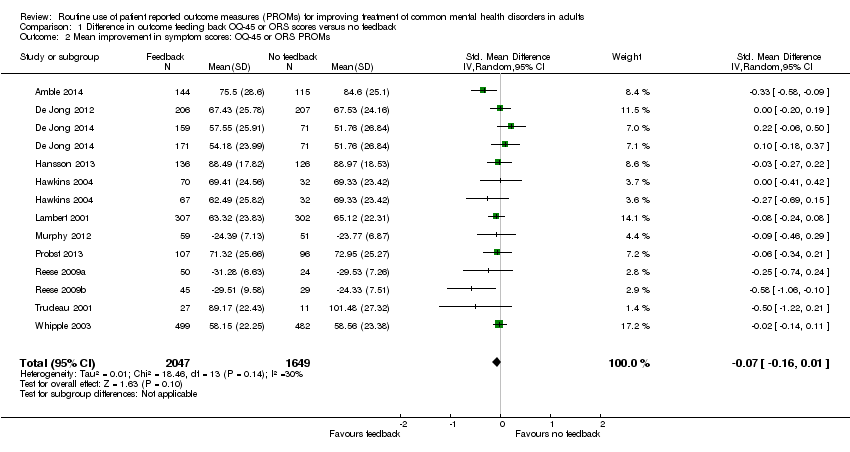
Comparison 1 Difference in outcome feeding back OQ‐45 or ORS scores versus no feedback, Outcome 2 Mean improvement in symptom scores: OQ‐45 or ORS PROMs.

Comparison 1 Difference in outcome feeding back OQ‐45 or ORS scores versus no feedback, Outcome 3 Number of treatment sessions received: all participants.

Comparison 2 Subgroup analysis: Setting, Outcome 1 Mean improvement in symptom scores by setting.
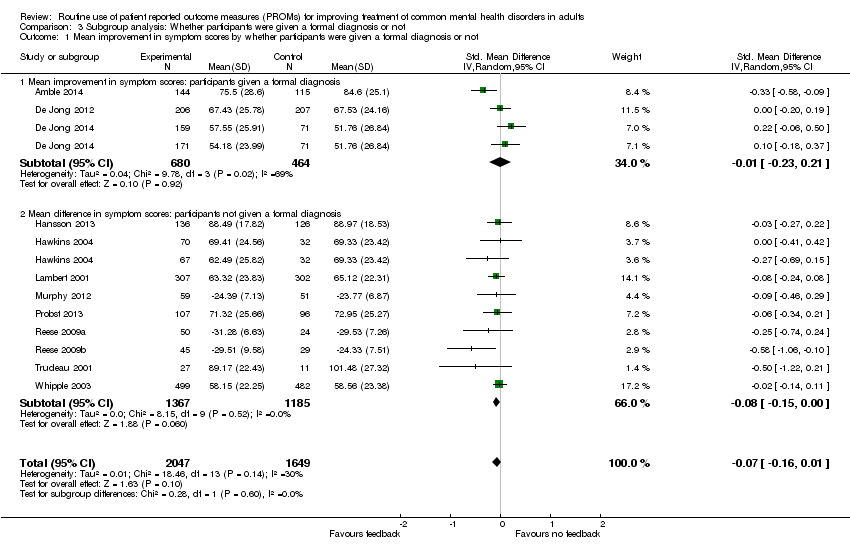
Comparison 3 Subgroup analysis: Whether participants were given a formal diagnosis or not, Outcome 1 Mean improvement in symptom scores by whether participants were given a formal diagnosis or not.
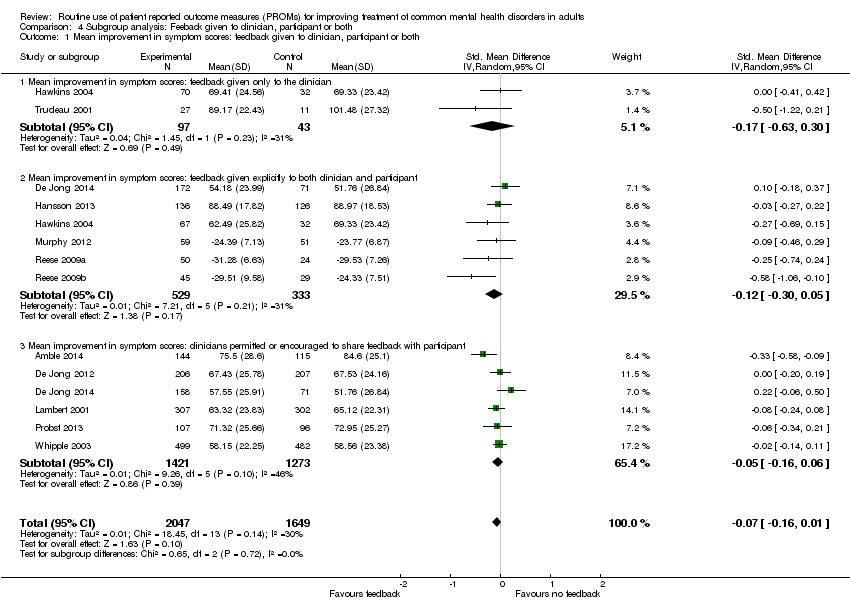
Comparison 4 Subgroup analysis: Feeback given to clinician, participant or both, Outcome 1 Mean improvement in symptom scores: feedback given to clinician, participant or both.

Comparison 5 Subgroup analysis: Whether feedback included treatment instructions or an algorithm, Outcome 1 Mean improvement in symptom scores by whether feedback included treatment instructions or an algorithm.

Comparison 6 Subgroup analysis: studies involving Michael Lambert versus studies not involving him, Outcome 1 Mean improvement in symptom scores by whether studies involved Michael Lambert.

Comparison 7 Post hoc analyses ‐ 'on track' and 'not on track' participants, Outcome 1 Mean improvement in symptom scores: 'not on track' participants only.

Comparison 7 Post hoc analyses ‐ 'on track' and 'not on track' participants, Outcome 2 Number of treatment sessions received by 'on track' and 'not on track' participants.
| Feedback of PROM scores for routine monitoring of common mental health disorders | |||||
| Patient or population: People with common mental health disorders1 Intervention: Feedback of PROM scores to clinician, or both clinician and patient Comparator: No feedback of PROM scores | |||||
| Outcomes and length of follow‐up | Illustrative risk | Number of participants | Quality of the evidence | Comments | |
| Assumed risk (range of means in no‐feedback groups) | Relative effect (95% CI) in feedback groups | ||||
| Mean improvement in symptom scores Follow‐up: 1‐6 months2 | Mean scores in no‐feedback groups ranged from 51.8 to 101.5 points for OQ‐45 and from 23.8 to 29.5 points for ORS. Standard deviations ranged from 17.8 to 28.6 points for OQ‐45 and from 7.1 to 9.6 points for ORS | Standard mean difference in symptom scores at end of study in feedback groups was 0.07 standard deviations lower | 3696 | ⊕⊕⊝⊝ | Neither study in the primary care setting used the OQ‐45 or ORS PROMs, and so could not be included in this meta‐analysis |
| Health‐related quality of life Follow‐up: 1‐5 months2 Medical Outcomes Study (SF‐12) physical and mental subscales). Scale from 0‐100 Follow‐up: 0‐1 year | Study results could not be combined in a meta‐analysis as data were not available in an appropriate format Mathias 1994 reported no significant differences between feedback and control groups on all nine domains of the SF‐36 Scheidt 2012 reported no significant differences between feedback and no‐feedback groups in physical or mental sub‐scale scores | 583 587 (1 study) | ⊕⊕⊕⊝ moderate7 | ||
| Adverse events Follow‐up: 6 months | Chang 2012 reported no immediate suicide risk across both feedback and no‐feedback groups combined. Number per group not given | 642 | ⊕⊕⊕⊝ moderate7 | ||
| Social functioning Follow‐up: 0‐1 year2 | Data for the social functioning subscale of the OQ‐45 were considered separately in Hansson 2013 and no difference was found | 262 (1 study) | ⊕⊕⊝⊝ low9 | ||
| Costs | Not estimable | 0 (0 studies) | No study assessed the impact of the intervention on direct or indirect costs | ||
| Changes in the management of CMHDs Changes in drug therapy and referrals for specialist care Follow‐up: 1‐6 months2 | Study results could not be combined in a meta‐analysis as data were not available in an appropriate format Chang 2012 and Mathias 1994 both reported no significant differences in changes in drug therapy between study arms Mathias 1994 reported mental health referrals were significantly more likely in the feedback group (OR 1.73, 95% CI 1.11 to 2.70) | 1215 | ⊕⊕⊕⊝ moderate7 | ||
| Changes in the management of CMHDs Follow‐up: 1‐6 months2 | Mean in no‐feedback groups ranged from 3.7 to 33.5 treatment sessions | Mean difference in number of treatment sessions in feedback groups was 0.02 lower | 2608 | ⊕⊕⊝⊝ | Post‐hoc analysis. Changes in medication and referrals for additional therapy were not assessed by any of these studies |
| CI: Confidence interval | |||||
| GRADE Working Group grades of evidence | |||||
| 1Studies were included if the majority of people diagnosed had CMHDs and no more than 10% had diagnoses of psychotic disorders, learning difficulties, dementia, substance misuse, or eating disorders 2Duration of therapy was variable in all studies and determined by the clinician or the patient, or both 6Downgraded two levels due to risk of bias (all included studies were judged at high risk of bias in at least two domains, in particular blinding of participants and outcome assessment, and attrition), and indirectness (although symptom scores were compared between feedback and non‐feedback groups, wider social functioning and quality‐of‐life measurements were not assessed in nearly all studies) 7Downgraded one level due to risk of bias (judged at high risk of bias in at least two domains, in particular blinding of participants and outcome assessment, and attrition) 8Number of PHQ‐9 questionnaires which contained reports of self‐harming thoughts 9Downgraded two levels due to risk of bias and imprecision, as total participant numbers were less than 400 10Downgraded two levels due to risk of bias and for imprecision: estimate of effect includes no effect and incurs very wide confidence intervals | |||||
| Outcome or subgroup title | No. of studies | No. of participants | Statistical method | Effect size |
| 1 Mean improvement in symptom scores: OQ‐45 PROMS Show forest plot | 9 | 3438 | Mean Difference (IV, Random, 95% CI) | ‐1.14 [‐3.15, 0.86] |
| 2 Mean improvement in symptom scores: OQ‐45 or ORS PROMs Show forest plot | 12 | 3696 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.07 [‐0.16, 0.01] |
| 3 Number of treatment sessions received: all participants Show forest plot | 7 | 2608 | Mean Difference (IV, Random, 95% CI) | ‐0.02 [‐0.42, 0.39] |
| Outcome or subgroup title | No. of studies | No. of participants | Statistical method | Effect size |
| 1 Mean improvement in symptom scores by setting Show forest plot | 12 | 3696 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.07 [‐0.16, 0.01] |
| 1.1 Multidisciplinary mental health care setting | 7 | 1848 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.05 [‐0.18, 0.07] |
| 1.2 Psychological therapy setting | 5 | 1848 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.10 [‐0.23, 0.03] |
| Outcome or subgroup title | No. of studies | No. of participants | Statistical method | Effect size |
| 1 Mean improvement in symptom scores by whether participants were given a formal diagnosis or not Show forest plot | 12 | 3696 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.07 [‐0.16, 0.01] |
| 1.1 Mean improvement in symptom scores: participants given a formal diagnosis | 3 | 1144 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.01 [‐0.23, 0.21] |
| 1.2 Mean difference in symptom scores: participants not given a formal diagnosis | 9 | 2552 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.08 [‐0.15, 0.00] |
| Outcome or subgroup title | No. of studies | No. of participants | Statistical method | Effect size |
| 1 Mean improvement in symptom scores: feedback given to clinician, participant or both Show forest plot | 12 | 3696 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.07 [‐0.16, 0.01] |
| 1.1 Mean improvement in symptom scores: feedback given only to the clinician | 2 | 140 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.17 [‐0.63, 0.30] |
| 1.2 Mean improvement in symptom scores: feedback given explicitly to both clinician and participant | 6 | 862 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.12 [‐0.30, 0.05] |
| 1.3 Mean improvement in symptom scores: clinicians permitted or encouraged to share feedback with participant | 6 | 2694 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.05 [‐0.16, 0.06] |
| Outcome or subgroup title | No. of studies | No. of participants | Statistical method | Effect size |
| 1 Mean improvement in symptom scores by whether feedback included treatment instructions or an algorithm Show forest plot | 12 | 3696 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.07 [‐0.16, 0.01] |
| 1.1 Mean improvement in symptom scores: treatment instructions or algorithm | 2 | 1184 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.03 [‐0.14, 0.09] |
| 1.2 Mean improvement in symptom scores: no treatment instructions or algorithm | 10 | 2512 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.09 [‐0.20, 0.02] |
| Outcome or subgroup title | No. of studies | No. of participants | Statistical method | Effect size |
| 1 Mean improvement in symptom scores by whether studies involved Michael Lambert Show forest plot | 9 | Std. Mean Difference (IV, Random, 95% CI) | Subtotals only | |
| 1.1 Mean improvement in symptom scores: studies involving Michael Lambert | 5 | 2032 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.06 [‐0.15, 0.03] |
| 1.2 Mean improvement in symptom scores: studies not involving Michael Lambert | 4 | 1406 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.02 [‐0.19, 0.15] |
| Outcome or subgroup title | No. of studies | No. of participants | Statistical method | Effect size |
| 1 Mean improvement in symptom scores: 'not on track' participants only Show forest plot | 10 | 923 | Std. Mean Difference (IV, Random, 95% CI) | ‐0.22 [‐0.35, ‐0.09] |
| 2 Number of treatment sessions received by 'on track' and 'not on track' participants Show forest plot | 5 | 2114 | Mean Difference (IV, Random, 95% CI) | 0.06 [‐0.91, 1.02] |
| 2.1 Number of treatment sessions received by "on track" participants only | 4 | 1633 | Mean Difference (IV, Random, 95% CI) | ‐0.69 [‐1.10, ‐0.29] |
| 2.2 Number of treatment sessions received by "not on track" participants only | 5 | 481 | Mean Difference (IV, Random, 95% CI) | 0.73 [‐2.04, 3.50] |
| Study ID | Response | Additional info | Outcome |
| No | Failed to respond | Email sent to [email protected] and [email protected] on 22 January 2015 regarding randomisation process, CGI‐S and PGI‐S outcomes and criteria for diagnosis | |
| Yes | Invited to become a co‐author | Replied immediately to an email sent on 17 June 2015. Provided details of data on OQ‐45 scores and further information on generation of random sequence and allocation concealment All data extraction was done by TK and MEG as KdJ became a co‐author of the review | |
| Yes | Reply on 28 January 2015 in response to email sent on 22 January: "We collected the data in a naturalistic setting at 2 clinics with clients who were already in treatment in some cases. We did collect outcome data over the course of the study period, but we do not have first and last measurements in all cases. I also do not have specific information regarding the clients (such as diagnoses). Therapists were aware which condition they were in as the independent variable was whether or not they received progress feedback. Clients did not know which condition they were in" | ||
| Yes | Emails sent to [email protected] on 22 January 2015, 29 July 2015 and 10 August 2015 enquiring about separate outcome data per diagnostic group. Reply on 30 August with requested information | ||
| No | Failed to contact | Study too old ‐ contact details of authors unobtainable | |
| No | Failed to respond | Email sent to [email protected]‐regensburg.de on 22 January 2015 regarding details of randomisation and blinding | |
| Yes | Reply on 3 February 2015 in response to email sent 22 January 2015: query about breakdown of outcome data per diagnostic group, with tabulated data provided | ||
| Yes | Reply on 3 February 2015 in response to email sent 22 January 2015: to query about randomisation, allocation concealment and outcome blinding: Randomisation: "When a client was assigned to a therapist, the first client was randomised using a random number generator to either the feedback or TAU condition. The second client was then assigned to the other condition." Allocation concealment: "This was done by the person who assigned clients at the respective centres. This was done after enrolment into the study. Investigators and client participants could not foresee which condition a participant would be placed into." Outcome blinding: "The researchers did not know which condition participants were in until the time of analysis." Query over discrepancy in data presented in main text and table: "The table is correct and it should be 4.69. That is what was used in the analyses as well." Further data regarding number of treatment sessions and standard deviations provided on request in December 2015 Further information provided on diagnoses of study participants on 3 May 2016, confirming that more than 90% of them would have had qualifying clinical diagnoses of anxiety or depressive disorders, or both | ||
| Yes | Reply on 26 March 2015 in response to email sent on 26 March 2015 enquiring about the details of managed care in place in some of the study participants, and about outcome data. "Managed care consisted of session limits and utilization review". Further email exchanges from 31 March to 2 April to enquire about blinding details. Reply on 13 May 2016 to email sent 13 May 2016, enquiring whether study participants would have met our review inclusion/exclusion characteristics, confirming that they would have met them | ||
| No | Failed to respond | Email sent to [email protected] on 22 January 2015 as listed as corresponding author on all four studies. Enquiries about randomisation procedure and allocation concealment. No reply regarding any of the studies was made. Further email sent to [email protected] and Michael Lambert on 17 July 2015, no reply received | |
| Yes | Email sent to [email protected] on 18 November 2015, reply received: further data provided on OQ‐45 outcomes and number of treatment sessions on 7 December 2015 |
| Study ID | Response | Additional info | Outcome |
| No | Failed to respond | Email sent to [email protected] and [email protected] on 22 January 2015 regarding randomisation process, CGI‐S and PGI‐S outcomes and criteria for diagnosis | |
| Yes | Invited to become a co‐author | Replied immediately to an email sent on 17 June 2015. Provided details of data on OQ‐45 scores and further information on generation of random sequence and allocation concealment All data extraction was done by TK and MEG as KdJ became a co‐author of the review | |
| Yes | Reply on 28 January 2015 in response to email sent on 22 January: "We collected the data in a naturalistic setting at 2 clinics with clients who were already in treatment in some cases. We did collect outcome data over the course of the study period, but we do not have first and last measurements in all cases. I also do not have specific information regarding the clients (such as diagnoses). Therapists were aware which condition they were in as the independent variable was whether or not they received progress feedback. Clients did not know which condition they were in" | ||
| Yes | Emails sent to [email protected] on 22 January 2015, 29 July 2015 and 10 August 2015 enquiring about separate outcome data per diagnostic group. Reply on 30 August with requested information | ||
| No | Failed to contact | Study too old ‐ contact details of authors unobtainable | |
| No | Failed to respond | Email sent to [email protected]‐regensburg.de on 22 January 2015 regarding details of randomisation and blinding | |
| Yes | Reply on 3 February 2015 in response to email sent 22 January 2015: query about breakdown of outcome data per diagnostic group, with tabulated data provided | ||
| Yes | Reply on 3 February 2015 in response to email sent 22 January 2015: to query about randomisation, allocation concealment and outcome blinding: Randomisation: "When a client was assigned to a therapist, the first client was randomised using a random number generator to either the feedback or TAU condition. The second client was then assigned to the other condition." Allocation concealment: "This was done by the person who assigned clients at the respective centres. This was done after enrolment into the study. Investigators and client participants could not foresee which condition a participant would be placed into." Outcome blinding: "The researchers did not know which condition participants were in until the time of analysis." Query over discrepancy in data presented in main text and table: "The table is correct and it should be 4.69. That is what was used in the analyses as well." Further data regarding number of treatment sessions and standard deviations provided on request in December 2015 Further information provided on diagnoses of study participants on 3 May 2016, confirming that more than 90% of them would have had qualifying clinical diagnoses of anxiety or depressive disorders, or both | ||
| Yes | Reply on 26 March 2015 in response to email sent on 26 March 2015 enquiring about the details of managed care in place in some of the study participants, and about outcome data. "Managed care consisted of session limits and utilization review". Further email exchanges from 31 March to 2 April to enquire about blinding details. Reply on 13 May 2016 to email sent 13 May 2016, enquiring whether study participants would have met our review inclusion/exclusion characteristics, confirming that they would have met them | ||
| No | Failed to respond | Email sent to [email protected] on 22 January 2015 as listed as corresponding author on all four studies. Enquiries about randomisation procedure and allocation concealment. No reply regarding any of the studies was made. Further email sent to [email protected] and Michael Lambert on 17 July 2015, no reply received | |
| Yes | Email sent to [email protected] on 18 November 2015, reply received: further data provided on OQ‐45 outcomes and number of treatment sessions on 7 December 2015 |